
Redis란?
REmote DIctionary Server
개요
•
인메모리 기반 key-value 구조의 저장소이다.
◦
•
key-value 구조이기 때문에 쿼리를 사용할 필요가 없다.
•
Single Threaded이다.
◦
한 번에 하나의 명령만 처리할 수 있다.
◦
중간에 처리 시간이 긴 명령어가 들어오면 그 뒤에 명령어들은 모두 앞에 있는 명령어가 처리될 때까지 대기가 필요하다.
◦
하지만 get, set 명령어의 경우 초당 10만 개 이상 처리할 수 있을 만큼 빠르다.
•
최적화된 C 코드로 작성되었다.
•
주요 Redis 사용 사례
◦
캐싱
◦
세션 관리
◦
pub/sub
◦
순위표
장점
빠른 성능
•
데이터를 디스크 또는 SSD에 저장하는 대부분의 데이터베이스와는 달리 모든 Redis 데이터는 서버의 주 메모리(RAM)에 저장된다.
•
Redis와 같은 인메모리 데이터베이스는 디스크에 액세스해야 할 필요를 없앰으로써 검색 시간으로 인한 지연을 방지하고 CPU 명령을 적게 사용하는 좀 더 간단한 알고리즘으로 데이터에 액세스할 수 있다.
•
일반적으로 작업을 실행하는 데 1밀초 미만이 소요된다.
인메모리 데이터 구조
•
다양한 데이터 유형에 매핑되는 키를 저장할 수 있다.
•
데이터 유형
◦
String
▪
기본 데이터 유형.
▪
텍스트 또는 이진 데이터.
▪
최대 크기 - 512MB
◦
List of Strings, Sets of unordered Strings
▪
문자열이 추가된 순서대로 유지된다.
◦
List
▪
Array 형식의 데이터 유형.
▪
처음과 끝에 데이터 삽입, 삭제는 빠르지만 O(1), 중간에 데이터를 삽입, 삭제하는 것은 느리다 O(N).
◦
Sorted Sets
▪
점수에 따라 정렬된다.
◦
Hashes
▪
필드와 값 목록을 저장.
◦
HyperLogLogs
▪
데이터 세트에서 고유한 항목을 센다.
다양성과 사용 편의성
•
Redis는 개발과 운영을 좀 더 쉽고 빠르게 수행할 수 있는 여러 도구를 제공한다.
•
Pub/Sub
◦
메시지를 채널에 게시하며, 채널에서 구독자에게 전달된다.
◦
채팅과 메시징 시스템에 매우 적합하다.
•
TTL Key
◦
특정 기간 후에 자동 삭제되는 Time To Live 값을 설정할 수 있다.
◦
데이터베이스를 불필요한 데이터로 채우지 않도록 하는데 유용하다.
•
원자성 카운터
◦
경합 상태가 일관성 없는 결과를 생성하지 않도록 한다.
•
Lua
◦
강력하지만 간단한 스크립트 언어이다.
복제 및 지속성
•
Redis는 master-slave 아키텍처를 사용하며 비동기식 복제를 지원하여 데이터가 여러 slave 서버에 복제될 수 있다.
•
이렇게 할 경우 주 서버에 장애가 발생하는 경우 요청이 여러 서버로 분산될 수 있으므로 향상된 읽기 성능과 복구 기능을 모두 제공할 수 있다.
•
Redis는 안정성을 제공하기 위해 특정 시점 스냅샷과 데이터가 변경될 때 마다 이를 디스크에 저장하는 Append Only File(AOF) 생성을 모두 지원한다.
◦
스냅샷 - Redis 데이터들을 디스크로 복사
•
스냅샷과 AOF을 통해 장애 발생 시 Redis 데이터를 신속하게 복원할 수 있다.
많은 개발 언어 지원
•
Redis 개발자는 100개가 넘는 오픈 소스 클라이언트를 사용할 수 있다.
•
Java, Python, PHP, C, C++, C#, JavaScript, Node.js, Go …
사용 사례
캐싱
•
다른 데이터베이스 “앞”에 배치된 Redis는 성능이 뛰어난 인메모리 캐시를 사용하여 엑세스 지연 시간을 줄이고, 처리량을 늘리며, 관계형 또는 NoSQL 데이터베이스의 부담을 줄인다.
세션 관리
•
Redis는 세션 관리 작업에 매우 적합하다.
•
세션키에 대한 적잘한 TTL과 빠른 key-value 저장소를 사용하면 간단하게 세션 정보를 관리할 수 있다.
실시간 순위표
•
Sorted Set 데이터 구조를 사용하면 요소가 목록에 유지되고 점수에 따라 정렬된다.
•
이를 통해 손쉽게 동적 순위표를 생성하여 게임 랭킹, 좋아요를 가장 많이 받은 메시지 등 다양한 사례에 적용할 수 있다.
속도 제한
•
Redis는 이벤트 속도를 측정하고 필요한 경우 제한할 수 있다.
•
클라이언트의 API 키에 연결된 Redis 카운터를 사용하여 특정 기간 동안 액세스 요청의 수를 세고 한도가 초과되는 경우 조치를 취할 수 있다.
•
속도 제한기는 포럼의 게시물 수를 제한하고, 리소스 사용량을 제한하며, 스팸을 억제하는데 주로 사용된다.
대기열
•
Redis List 데이터 구조를 사용하면 간단한 영구 대기열을 손쉽게 구현할 수 있다.
•
Redis List는 자동 작업 및 차단 기능을 제공하므로 신뢰할 수 있는 메시지 브로커 또는 순환 목록이 필요한 다양한 어플에 적합하다.
채팅 및 메시징
•
Redis에서는 패턴 매칭과 더불어 Pub/Sub 을 지원한다.
•
따라서 고성능 채팅방, 실시간 코멘트 스트림 및 서버 상호 통신을 지원할 수 있다.
•
Pub/Sub 을 사용하여 게시된 이벤트를 기반으로 작업을 트리거할 수 있다.
Redis Replication
복제란?
•
Redis의 데이터를 거의 실시간으로 다른 Redis 노드에 복사하는 작업이다.
•
따라서 서비스를 제공하던 첫 번째 Redis 노드가 다운되더라도, 데이터를 받은 두 번째 Redis 노드가 서비스를 계속 할 수 있다.
•
Redis에서는 첫 번째 노드를 master라고 하고 두 번째 노드를 replica(복제)라고 합니다.
•
복제 기능이 없을 경우
◦
Redis 인스턴스가 사람의 실수 또는 소프트웨어적인 문제로 다운 되었을 때 AOF 기능을 사용하고 있었고 데이터가 많이 쌓여 있다면, 인스턴스가 시작하는데 몇 분이 걸릴 수도 있다.
◦
다운의 원인이 하드웨어적인 문제였다면 서비스를 다시 시작하는 상당한 시간이 소요될 수 있고, 데이터를 복구하지 못할 수도 있다.
•
master와 replica는 물리적으로 다른 머신에 두어야 한다.
특징
•
Redis는 비동기 복제를 한다.
•
Redis master는 복제 서버를 여러 개 둘 수 있다.
•
복제 서버는 또 복제 서버를 둘 수 있다.
◦
master → 복제1 → 복제2 이런 구성이 된다.
•
master에 많은 데이터가 있는 상태에서 복제 서버를 시작하면, 대량의 master 데이터가 복제 서버로 보내진다. 이 때에도 master는 멈추지 않고 정상적으로 요청을 처리한다. 왜냐하면 데이터를 복제 서버로 보내는(RDB 파일을 생성하는) 작업은 자식 프로세스가 처리한다.
•
복제 서버에게 조회 요청을 처리하도록 하는 것도 부하를 분산하는 좋은 방법이다.
◦
특히 sort 명령같은 것들은 복제 서버에서 수행하는 것이 좋다.
•
master의 부하를 줄이기 위해서, AOF 쓰기나 RDB 파일 생성을 복제 서버에서 수행하는 것도 좋은 방법이다.
◦
하지만 이런 설정을 했을 경우에 master를 자동 시작 하도록 하면 데이터가 유실 될 수 있다.
복제 방식
전체 동기화(full synchronization)
Redis 2.8.18 부터는 RDB 파일을 디스크에 만들지 않고 복제하는 기능을 제공
•
복제 순서
1.
master는 자식 프로세스를 시작해 백그라운드로 RDB파일에 데이터를 저장.
2.
데이터를 저장하는 동안 master에 새로 들어온 명령들은 처리 후 복제버퍼에 저장.
3.
RDB 파일 저장이 완료되면, master는 파일을 복제 서버에게 전송.
4.
복제 서버는 파일을 받아 디스크에 저장하고, 메모리로 로드.
5.
master는 복제버퍼에 저장된 명령을 복제 서버에게 전송.
•
master가 다운 되면 복제 서버는 1초에 한 번씩 master에 Connect 요청을 보낸다.
•
master가 살아나면 복제 서버에 복제 순서에 따라 Sync를 한다.
•
복제 서버가 여러 개 일때도 RDB 파일은 하나만 생성한다.
부분 동기화(Partial resynchronization)
부분 동기화 기능은 Redis 버전 2.8 부터 제공
•
master와 복제 서버는 각 서버의 run id 와 replication offset을 가지고 있다.
•
master와 복제 서버간 네트워크가 끊어지면 master는 복제 서버에 전달할 데이터를 backlog-buffer에 저장한다.
•
다시 연결되었을 때 backlog-buffer가 넘치지 않았으면 run id와 offset을 비교해서 그 이후 부터 동기화를 한다.
◦
이것을 부분 동기화라고 한다.
•
•
네크워트 단절 시간이 길어져 master의 backlog-buffer가 넘치면 다시 연결되었을 때 전체 동기화를 한다.
•
master나 복제 서버 중 한쪽이 재시작 했을 경우에도 전체 동기화를 한다.
master: 디스크를 사용하지 않는 동기화 (Diskless Replication)
Redis 버전 2.8.18 부터 디스크를 사용하지 않는 동기화 기능을 제공
•
이 기능은 Redis를 캐시 용도로 사용할 경우 또는 master가 설치된 머신의 디스크 성능이 좋지 않을 경우 이용할 수 있다.
◦
디스크를 사용하지 않는 것은 master만 적용된.
◦
복제 서버는 받은 데이터를 RDB 파일에 저장한다.
◦
master의 자식 프로세스가 RDB 데이터를 소켓을 통해서 복제 서버에게 직접 쓰는 방식이다.
•
redis.conf(Master) 파라미터를 통해 설정한다.
◦
repl-diskless-sync no or yes, default no
◦
디폴트는 no, yes로 하면 디스크를 사용하지 않고 동기화가 된다.
•
여러 복제 서버에서 요청이 들어올 경우, 기본적으로 첫 번째 복제 서버의 소켓에 데이터를 전송하고, 완료되면, 다음 복제을 처리한다.
•
몇 개 복제 서버를 한 번에 처리할 수 있도록 요청을 기다리는 옵션.
◦
redis.conf(Master) 파라미터를 통해 설정한다.
▪
첫 번째 요청이 온 후 5초 동안 다른 복제 서버의 요청을 기다렸다가, 요청이 오면 같이 처리한다.
▪
즉, 5초 안에 3개 복제 서버에서 동기와 요청이 왔다면 이는 병렬로 처리할 수 있다.
▪
즉시 처리하도록 하려면 0으로 설정.
복제(Replica): 디스크를 사용하지 않는 동기화 (repl-diskless-load)
이 기능은 버전 6.0부터 사용할 수 있다
•
복제 서버에서 디스크를 사용하지 않는 동기화이다.
◦
즉, 복제 서버에 RDB 파일을 생성하지 않는다.
•
redis.conf(Replica) 파라미터를 통해 설정한다.
◦
repl-diskless-load disabled/on-empty-db/swapdb, default disabled 세 가지.
•
disabled
◦
diskless를 사용하지 않는다.
•
on-empty-db
◦
복제 서버에 데이터(키)가 없을 경우에 적용, 데이터가 있으면 RDB 파일을 생성해서 복제한다.
•
swapdb
◦
복제 서버에 데이터(키) 여부와 상관없이 diskless로 동작한다.
◦
이 경우 만약의 사태에 대비해서 기존 데이터를 메모리(RAM)에 보존한다.
◦
복제가 성공하면 RAM에 보존한 데이터는 지운다.
◦
복제가 실패하면 RAM에 보존한 데이터로 복구한다.
▪
이 경우 기존 데이터 + 새 데이터 만큼 메모리(RAM)이 필요하므로 충분한 메모리가 있어야 한다.
복제 서버는 읽기 전용
Redis 버전 2.6 부터 복제 서버는 디폴트로 읽기 전용이다
•
redis.conf 파라미터를 통해 설정한다.
◦
replica-read-only yes or no, default yes
•
복제 서버에 데이터를 입력 했어도 master와 Resync 되면 복제 서버에 입력된 데이터는 사라진다.
Redis Cluster
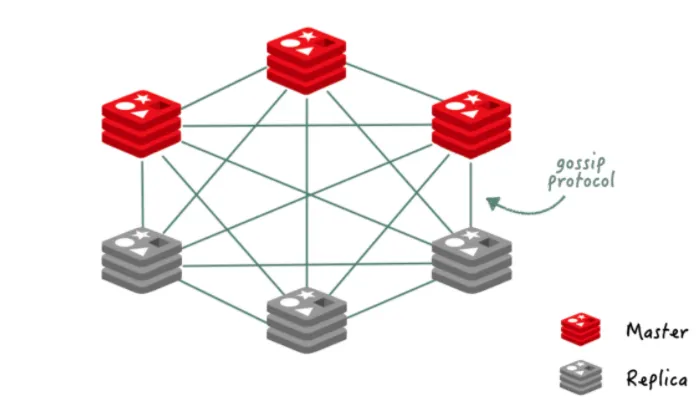
주요 기능
•
자동 장애 조치(Automatic Failover)
•
샤딩 (sharding)
◦
데이터를 분산 저장
동작 방식
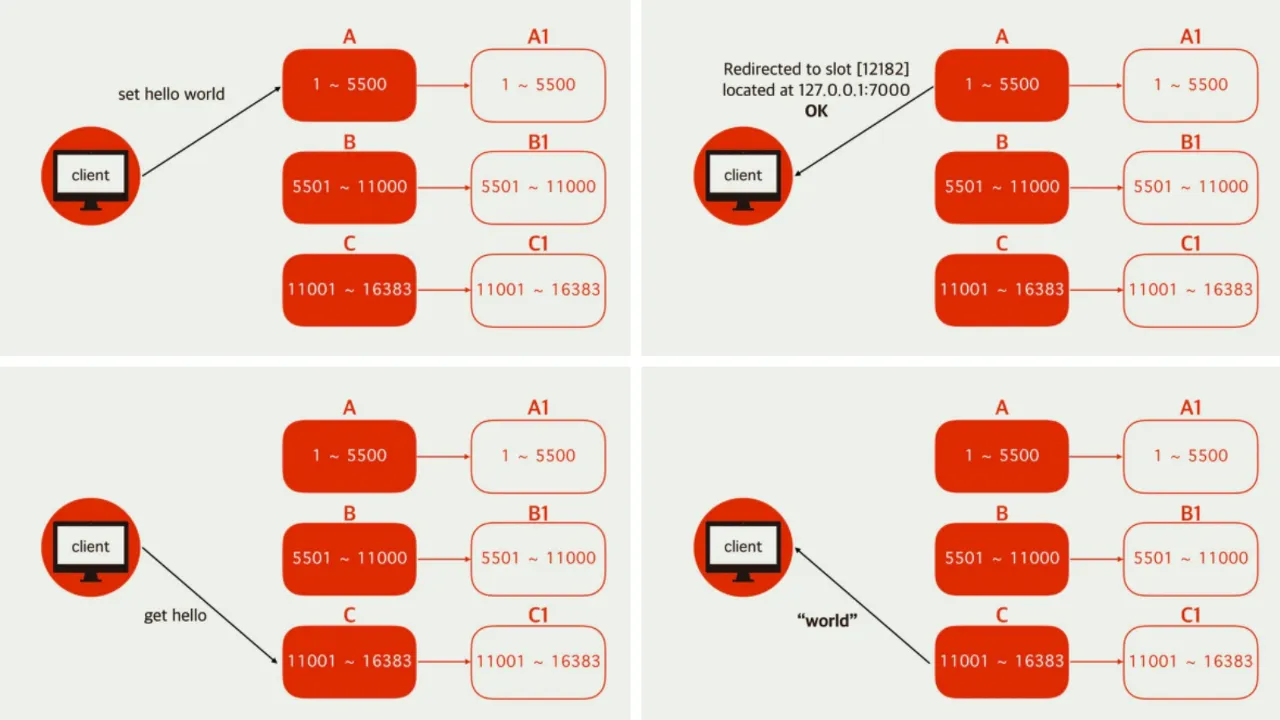
•
master 1,2,3 이 있다면 데이터는 3개중에 하나에 저장되며, client 가 데이터 읽기 요청시 저장된 곳이 아닌 다른 master에 요청 했다면 저장된 master 정보를 알려주며, 클라이언트는 전달받은 master 정보에 다시 요청해서 데이터를 받아와야 한다.
◦
해당 부분은 Redis Cluster 를 지원하는 라이브러리에서 다 해준다.
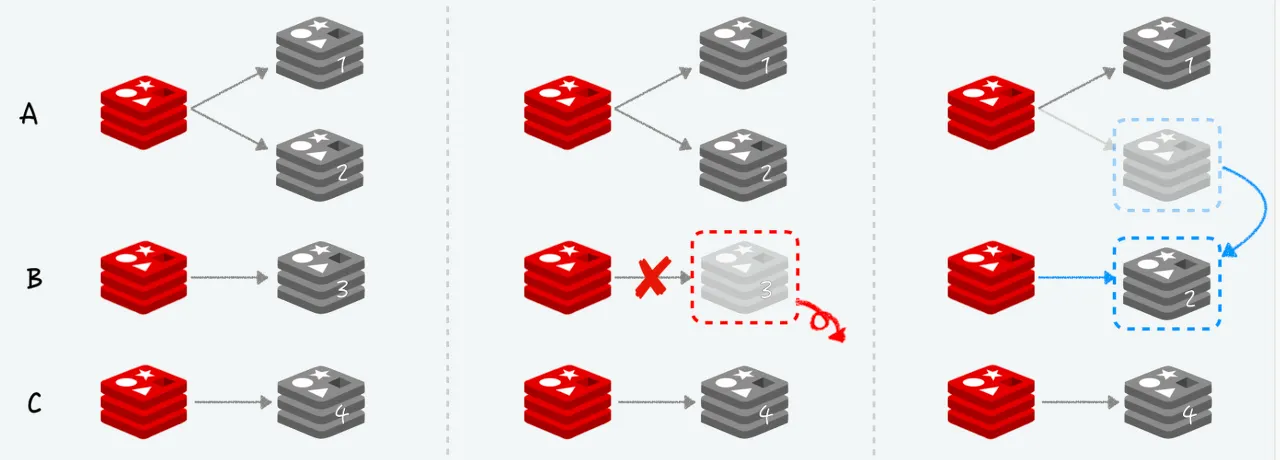
•
slave 가 죽어서 복제 노드가 없는 master가 생길시 다른 master 노드에 여유분이 있다면 해당 노드로 빈자리를 채울 수 있다.
◦
사용자가 개입하지 않고 Redis Cluster가 알아서 다 해준다.
•
◦
해시 슬롯
▪
CRC-16 해시 함수를 이용해 key를 정수로 변환하고 해당 정수값을 16,385로 모듈 연산한 값.
▪
해시 함수는 CRC16 function을 사용한다.
◦
cluster는 총 16384개의 해시 슬롯이 있으며 각 master 노드에 자유롭게 할당 가능.
▪
Redis 노드가 3개 일 경우, 1번 노드는 0-5460, 2번 노드는 5461-10922, 3번 노드는 10923-16383 슬롯을 가지게 된다.
•
슬롯을 노드에 할당하는 것은 Redis Cluster가 한다.
•
master가 죽을 경우 master의 slave는 gossip Protocol을 통해 master의 죽음을 파악하고, slave중 하나가 master로 failover된다.
◦
→ 중단없는 서비스 제공.
◦
failover가 발생한다면, slave가 master로 승격할 때까지, 문제가 발생한 master로 할당된 슬롯의 키는 사용할 수 없다.
•
기존 master가 다시 살아나면 새로운 master의 slave가 된다.
gossip Protocol
•
각 Redis는 다른 Redis들과 직접 연결하여 상태 정보를 통신.
특징
•
Redis Cluster에서는 별도의 Sentinel이 필요하지 않다.
•
Sentinel보다 더 발전된 형태이다.
•
최소 3개의 master 노드가 있어야 구성 가능하다.
•
Sentinel이 노드를 감시했지만, Cluster에서는 모든 노드가 서로 감시한다.
•
Multi-master, Multi-slave 구조이다.
◦
1000대의 노드까지 확장 가능하다.
◦
모든 데이터는 master 단위로 샤딩되고 slave 단위로 복제된다.
◦
master 마다 최소 하나의 slave를 두는 것을 추천한다.
◦
slave가 하나도 없을 때 master 노드가 작동이 안되면 해당 데이터 유실이 발생한다.
•
노드를 추가/삭제할 때 운영 중단 없이 Hash slot을 재구성할 수 있다.
•
키 이동 시에 해당 키에 잠시 락이 걸릴 수 있다.
•
과반수 이상의 노드가 다운되면 cluster가 깨진다.
•
Replication은 Async방식으로 이루어지기 때문에 Data 정합성이 깨질 수 있는데 이때 나중에 master가 된 Data를 기준으로 정합성을 맞춘다.
•
Redis Cluster는 2개의 포트가 필요하다.
◦
클라이언트를 위한 포트, 노드 간 통신 버스 포트
•
gossip Protocol은 Redis Client가 이용하는 Port번호보다 10000높은 port 번호를 이용한다.
Redis Cluster 제한 사항
Redis 버전 3.0 이상에서 클러스터를 사용할 수 있다.
•
기본적으로 멀티 키 명령(operation)을 수행할 수 없다.
◦
예를 들어, MSET key1 value1 key2 value2, SUNION key1 key2, SORT 이런 명령은 클러스터에서 사용할 수 없다.
◦
하지만 hash tag를 사용하면 사용할 수 있다.
◦
Hash tag는 키의 일부를 {}로 감싸는 것이다.
▪
예를 들어, {user001}.following과 {user001}.followers는 같은 슬롯에 저장된다.
•
클러스터 모드에서는 DB 0번만 사용할 수 있다.
•
멀티 키 명령에 대해서
◦
Enterprise 게이트 서버를 사용하면 멀티 키 명령을 사용할 수 있다.
Redis Sentinel
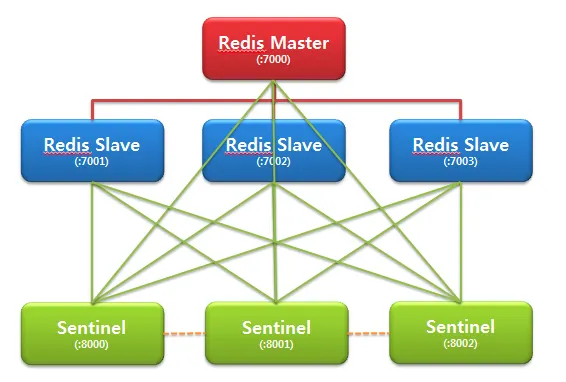
•
운영중 예기치 않게 master가 다운되었다면, 관리자가 이를 감지해서 slave를 master로 올리고 클라이언트들이 새로운 master에 접속할 수 있도록 해 주어야 한다.
•
Sentinal은 master와 slave를 감시하고 있다가 master가 다운되면 이를 감지해서 관리자의 개입없이 자동으로 slave를 master로 올려준다.
주요 기능
•
모니터링 Monitoring
◦
Sentinal은 Redis master, slave들을 제대로 동작하는지 지속적으로 감시한다.
•
자동 장애조치 Automatic Failover
◦
Sentinal은 master가 예기치 않게 다운되었을 때 slave를 새로운 master로 승격시켜 준다.
◦
그리고 slave가 여러 대 있을 경우 이 slave들이 새로운 master로 부터 데이터를 받을 수 있도록 재 구성하고, 다운된 master가 재 시작했을 때 slave로 전환되어 새로운 master를 바라볼 수 있도록 한다.
•
알림 Notification
◦
Sentinal은 감시하고 있는 Redis 인스턴스들이 failover 되었을 때 Pub/Sub으로 Application(client)에게 알리거나 shell script로 관리자에게 이메일이나 SMS로 알릴 수 있다.
동작 방식
•
Sentinal 인스턴스 과반 수 이상이 master 장애를 감지하면 slave 중 하나를 master로 승격시키고 기존의 master는 slave로 강등시킨다.
•
slave가 여러개 있을 경우 slave가 새로운 master로부터 데이터를 받을 수 있도록 재구성된다.
failover 감지 방법
•
SDOWN : Subjectively down (주관적 다운)
◦
Sentinal에서 주기적으로 master에게 보내는 PING과 INFO 명령의 응답이 3초(down-after-milliseconds 에서 설정한 값) 동안 오지 않으면 주관적 다운으로 인지한다.
◦
Sentinal 한 대에서 판단한 것으로, 주관적 다운만으로는 장애조치를 진행하지 않는다.
•
ODOWN : Objectively down (객관적 다운)
◦
설정한 quorum 이상의 Sentinal에서 해당 master가 다운되었다고 인지하면 객관적 다운으로 인정하고 장애 조치를 진행한다.
Quorum
•
Redis 장애 발생시 몇 개의 Sentinel이 특정 Redis의 장애 발생을 감지해야 장애라고 판별하는지를 결정하는 기준 값.
•
보통 Redis의 과반 수 이상으로 설정한다.
failover시 주의 사항
•
get-master-addr-by-name
◦
master, slave 모두 다운되었을 때 Sentinel에 접속해 master 서버 정보를 요청하면 다운된 서버 정보를 리턴한다.
◦
따라서 INFO Sentinel 명령으로 마스터의 status를 확인해야 한다.
•
slave -> master 승격 안되는 경우
◦
slave다운 → master다운 → 다운된 slave 재시작되면 이 서버는 master로 전환되지 않는다.
◦
slave의 redis.conf에 자신이 복제로 되어 있고, Sentinel도 복제라고 인식하고 있기 때문이다.
◦
해결책은 slave가 시작하기 전에 redis.conf에서 slaveof를 삭제하는 것이다.
•
Failover Timeout 만큼 write 연산 실패
◦
데이터량에 따른 최적의 Failover Timeout값을 찾고 sentinel.conf에 적용해야 한다.
특징
•
Sentinel은 1차 복제만 master 후보에 오를 수 있다.
◦
복제 서버의 복제 서버는 불가능
•
1차 복제 서버 중 replica-priority 값이 가장 작은 서버가 master에 선정된다.
◦
0으로 설정하면 master로 승격 불가능하고 동일한 값이 있을 땐 엔진에서 선택한다.
•
안정적 운영을 위해 3개 이상의 Sentinal을 만드는 것을 권장하는데, 서로 물리적으로 영향받지 않는 컴퓨터나 가상 머신에 설치되는 것이 좋다.
•
Sentienl은 내부적으로 Redis 의 Pub/Sub 기능을 사용해서 서로 정보를 주고 받는다.
•
Sentienl + Redis 구조의 분산 시스템은 Redis가 비동기 복제를 사용하기 때문에 장애가 발생하는 동안 썼던 내용들이 유지됨을 보장할 수 없다.
•
Sentinel을 Redis와 동일한 Node에 구성해도 되고, 별도로 구성해도 된다
•
클라이언트는 주어진 서비스를 담당하는 현재 Redis master의 주소를 요청하기 위해 Sentinel에 연결한다.
◦
장애 조치가 발생하면 Sentinel은 새 주소를 알려준다.
정리

Cluster를 사용하자
•
Sentinel은 One Master 구조이기 때문에 데이터 사이즈가 커지면 Scale Up을 해야하는데, Cluster는 Scale Out이 가능하다.
•
추후 확장성을 위해 Cluster를 사용하는 것이 좋다.





