Kafka란?
Apache Kafka는 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션에 사용되는 오픈 소스 분산 이벤트 스트리밍 플랫폼입니다.
https://kafka.apache.org/
Apache Kafka는 전통적인 엔터프라이즈 메시징 시스템의 대안이다.
용어 정리
•
Topic
◦
카프카에서 메시지 피드를 구분하기 위한 저장소
•
Partition
◦
병렬 처리 및 고성능을 얻기 위해 하나의 토픽을 여러 개로 나눈 것
•
Replication
◦
각 메시지들(파티션)을 여러 개로 복제해서 카프카 클러스터 내 다른 브로커에 분산시키는 동작
•
Replication Factor
◦
리플리케이션 동작 시 같은 메시지를 가지는 파티션의 총 개수 (= 원본 + 복제본)
•
최소 리플리케이션 수(min.insync.replicas)
◦
프로듀서가 acks 옵션을 all로 설정하여 메시지 전송 시, write 성공 확인을 위해 충족해야 하는 기준 (복제 완료 개수)
•
Offset
◦
파티션의 메시지가 저장되는 위치 (64bit 정수)
•
Commit
◦
ISR 내에서 모든 팔로워의 복제가 완료됨을 표시하는 동작
•
Segment
◦
프로듀서가 전송한 메시지가 브로커의 로컬 디스크에 저장된 것
•
Leader
◦
리플리케이션 팩터 중 실제로 읽기와 쓰기 동작을 담당하는 파티션
•
Followe
◦
리더의 메시지를 복사하여 저장하는 파티션
•
Controller
◦
ISR 관리와 리더 선출을 담당하는 브로커
•
ISR(InSyncReplica)
◦
동일한 메시지를 갖고 있는 가용한 리더와 팔로워를 묶는 논리적 그룹
•
High-Water-Mark
◦
마지막 커밋 오프셋의 위치
•
Leader Epoch
◦
컨트롤러가 과거에 선출했던 리더의 수 (32bit 정수)
기본 명령어
카프카를 사용할 때 주로 사용하는 기본 명령어
Kafka의 bin 풀더에서 확인 가능

•
kafka-topics.sh
◦
토픽을 생성하거나 토픽 설정 등을 변경하기 위해 사용.
•
kafka-console-producer.sh
◦
토픽으로 메시지를 전송하기 위해 사용.
•
kafka-console-consumer.sh
◦
토픽에서 메시지를 가져오기 위해 사용.
•
kadka-reassign-partitions.sh
◦
토픽의 파티션과 위치 변경 등을 위해 사용.
•
kafka-dump-log.sh
◦
파티션에 저장된 로그 파일의 내용을 확인하기 위해 사용.
Kafka 특징
•
Middleware for streaming data
◦
Kafka는 스트리밍 데이터를 다루기 위한 미들웨어와 그 주변 생태계를 말한다.
•
Highly scalable/available
◦
높은 확장성(scalability)과 가용성(availability)을 갖추고 있다.
◦
Apache.org에 따르면, “Kafka는 서버에 50KB, 또는 50TB의 영구 스토리지가 있더라도 동일한 성능을 발휘"한다고 한다.
•
Data persistency
◦
데이터 영속성(persistency)을 지원한다.
◦
Kafka에 한 번 입력된 데이터는 그 시점에서 영속화되었다고 볼 수 있다는 의미다.
•
Supports Pub-Sub model
◦
Pub/Sub 모델을 사용한 데이터 분포를 지원한다.
•
Supports Message Queue
◦
메시지 큐로서 메시지가 한 번 소비되고 처리될 수도 있다.
◦
Kafka는 메시지 큐로 자주 언급되지만, 더 정확하게는 분산 이벤트 스트리밍 플랫폼으로 설명하는게 적절하다.
◦
Kafka는 확실히 메시지 큐로 사용될 수 있지만, 그 아키텍처와 기능은 전통적인 메시지 큐 시스템을 넘어선다.

스트리밍 데이터이란?
스트리밍 데이터는 실시간 정보의 지속적인 흐름이자 이벤트 기반 아키텍처 소프트웨어 모델의 기반이다. 현대적인 애플리케이션은 스트리밍 데이터를 사용하여 데이터를 처리, 저장, 분석한다.
스트리밍 데이터는 데이터 세트에 발생한 변경 사항이나 이벤트의 실행 로그라고 볼 수도 있다.
이벤트 스트리밍이란?
이벤트 스트리밍은 데이터의 시간적 가치를 포착하는 것은 물론 흥미로운 일이 발생할 때마다 조치를 취하는 푸시 기반 애플리케이션을 만들기 위해 이벤트가 생성되는 대로 이벤트의 무한 스트림을 지속적으로 처리하는 프로세스이다.
이벤트 스트리밍의 예로는 고객 대면 웹 애플리케이션에서 생성되는 로그 파일을 지속적으로 분석하는 것, 사용자가 전자상거래 웹사이트를 탐색할 때 고객 행동을 모니터링하고 그에 대응하는 것, 소셜 네트워크에서 생성되는 클릭 스트림 데이터의 변화를 분석하여 고객 감정에 지속적으로 영향을 미치는 것, 사물 인터넷(IoT) 기기에서 생성되는 원격 분석 데이터를 수집하고 그에 대응하는 것 등이 포함된다.
탄생 배경
•
하루에 1조 4천억 건의 메시지를 처리하기 위해 LinkedIn이 개발한 내부 시스템으로 시작했으나, 현재 이는 다양한 기업의 요구 사항을 지원하는 애플리케이션을 갖춘 오픈소스 데이터 스트리밍 솔루션이 되었다.
주로 쓰이는 곳
Kafka는 주로 2가지 종류의 애플리케이션 개발에 쓰인다.
•
실시간 스트리밍 데이터 파이프라인
◦
엔터프라이즈 시스템 간에 무수히 많은 데이터/이벤트 레코드를, 규모의 제약 없이 실시간으로 전송하도록 설계된 애플리케이션이다.
◦
레코드 전송은 안정적으로, 그리고 데이터 손상 및 중복을 비롯하여 방대한 데이터의 고속 이동 과정에서 흔히 발생하는 각종 문제점 없이 이루어진다.
•
실시간 스트리밍 애플리케이션
◦
레코드 또는 이벤트 스트림에 의해 구동되는 애플리케이션, 그리고 자체적으로 스트림을 생성하는 애플리케이션이다.
◦
온라인에서는 이러한 애플리케이션을 매일 수없이 만날 수 있다. 가까운 매장의 제품 재고량을 계속 업데이트하는 리테일 사이트, 클릭스트림 분석을 토대로 개인별 추천이나 광고를 보여주는 사이트 등이 이에 해당한다.
Kafka 작동 방식
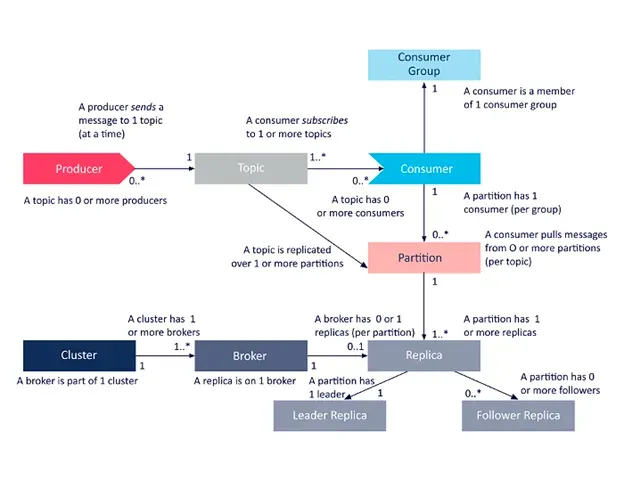
Kafka에는 3가지 주요 기능이 있다.
1.
애플리케이션에서 데이터 또는 이벤트 스트림을 게시하거나 구독할 수 있게 한다.
2.
장애가 발생하더라도 안전하고 안정적인 방식으로 정확하게 (이를테면 생성된 순서대로) 레코드를 저장한다.
3.
레코드를 (생성되는 순서대로) 실시간 처리한다.
•
Producer
◦
애플리케이션에서 어떤 Kafka 토픽에 스트림을 게시하는 것이 가능하다.
◦
토픽(topic)이란 이름이 지정된 로그이며, 레코드를 생성되는 상대적 순서대로 저장한다.
◦
어떤 토픽에 기록된 레코드는 변경하거나 삭제할 수 없다. 미리 구성된 기간(예: 2일) 동안, 또는 스토리지 공간이 소진될 때까지 해당 토픽에 남아 있다.
▪
이 레코드를 변경 불가능한 커밋 로그라고 한다.
•
변경 불가능하다고 하는 것은 레코드를 추가할 수는 있지만 달리 변경할 수는 없기 때문이다.
•
Broker cluster
◦
임의 개수의 노드로 구성되는 클러스터로 'topic'이라고 불리는 데이터 관리 유닛을 임의 개수만큼 호스팅할 수 있다.
◦
Producer는 그 중 하나의 topic을 대상으로 데이터를 입력한다.
•
Consumer
◦
애플리케이션에서 하나 이상의 topic을 구독하고 해당 topic에 저장된 스트림(데이터)을 입수하고 처리할 수 있다.
▪
해당 topic의 레코드를 실시간으로 다루거나, 과거의 레코드를 입수하고 처리할 수 있다.
◦
여기서 중요한 특성은 하나의 topic에 여러 개의 Consumer가 각각 다른 목적으로 존재한다는 점이다.
◦
일단 topic에 입력된 데이터는 여러 Consumer가 서로 다른 처리를 하기 위해 여러 번 가져올 수 있다.
▪
이것이 바로 Pub/Sub라고 불리는 데이터 분포 모델이다.
•
Streams
◦
Producer 및 Consumer를 기반으로 복잡한 처리 기능을 추가한다. 이 기능은 애플리케이션에서 상시 프론트-백 스트림 처리를 수행할 수 있게 한다.
◦
즉, 하나 이상의 토픽에서 레코드를 소비하거나, 필요에 따라 레코드를 분석, 집계, 변환하거나, 결과로 생성된 스트림을 같은 토픽이나 다른 토픽에 게시할 수 있다.
◦
Producer와 Consumer는 단순 스트림 처리에 사용할 수 있으나, 더 정교한 데이터/이벤트 스트리밍 애플리케이션 개발은 스트림 API에서 가능하다.
•
Connector
◦
커넥터란 재사용 가능한 생산자 또는 소비자이며, 데이터 소스를 Kafka 클러스터에 통합하는 것을 간소화하고 자동화한다.
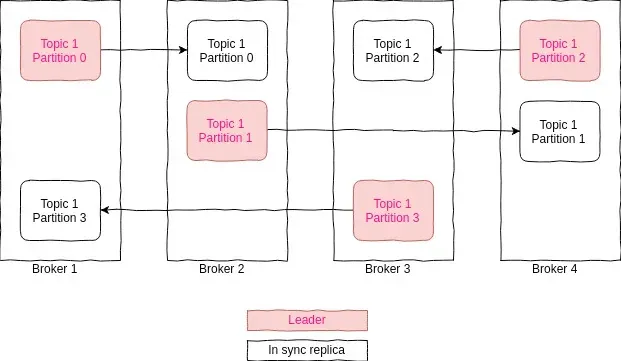
Replication
•
우리는 Kafka를 클러스터로 사용한다. 이는 Kafka의 데이터가 여러 서버에 분산되어 있다는 것을 의미한다.
•
Replication은 브로커 중 하나가 다운되어 요청을 처리할 수 없는 경우에 대비하여 가용성만을 위해 여러 개의 데이터 복사본을 갖는 프로세스이다.
•
Kafka에서 Replication는 파티션 세분성(partition granularity)에서 발생한다.
◦
즉, 파티션의 복사본은 파티션의 미리 쓰기 로그를 사용하여 여러 브로커 인스턴스에서 유지된다.
•
Kafka에서 리플리케이션(Replication)이란, 각 메시지들을 여러 개로 복제해서 카프카 클러스터 내 브로커들에 분산시키는 동작을 의미한다.
•
이러한 리플리케이션 동작 덕분에 하나의 브로커가 종료되더라도 카프카는 안정성을 유지할 수 있다.
Replication factor
kafka-topics.sh --bootstrap-server localhost:9092 --replication-factor 1 --partitions 3 --topic test --create
Shell
복사
Kafka Topic 생성 command
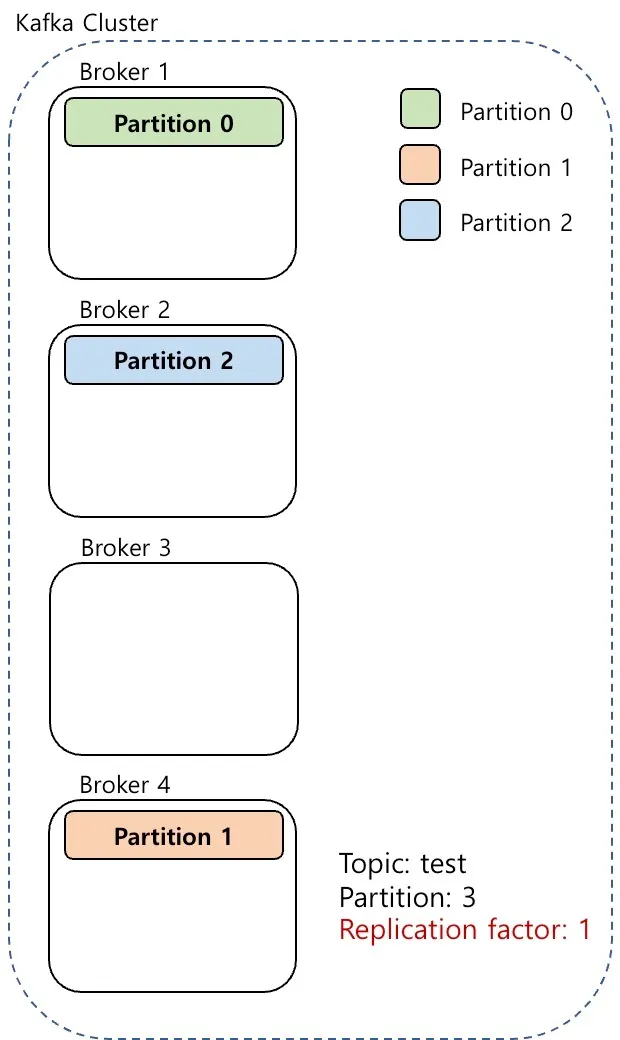
kafka-topics.sh --bootstrap-server localhost:9092 --replication-factor 1 --partitions 3 --topic test --create
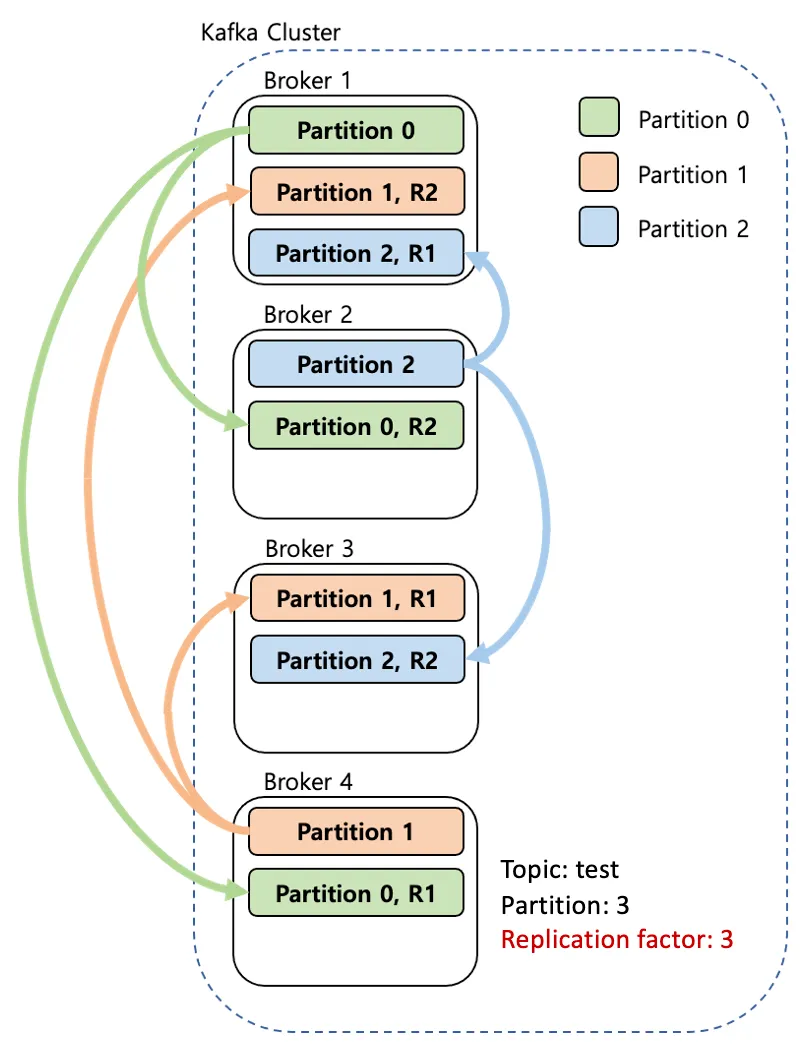
--bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic test --create
•
Replication factor는 보관해야 하는 파티션의 복사본 수를 정의한다.
•
Kafka의 Replication 동작을 위해 Topic 생성 시 필수값으로 Replication factor라는 옵션을 설정해야 한다.
•
Kafka에서는 이렇게 Replication factor 수를 조정하여, Replication의 수를 몇 개로 할지 관리자가 조정할 수 있다.
•
Replication 수가 많을수록 브로커 장애 발생 시 Topic에 저장된 데이터 안전성이 보장되기 때문에 중요 데이터의 경우 Replication factor 수를 1보다는 높게 사용하는 것를 권장한다. (데이터 중요도에 따라 보통 2~3)
◦
정확히는 Kafka의 Topic이 Replication 되는 것이 아니라 Partition이 Replication 되는 것이다.
◦
당연하지만 각각의 Replication factor 숫자만큼 브로커가 필요하다.
•
Replication factor 수가 커질수록 당연히 안정성은 높으나 브로커의 resource를 많이 사용하게 된다.
Leader & Follower
RabbitMQ의 경우 복제본이 2개 있는 경우 하나는 Master, 나머지는 Mirrored라고 표현합니다.
이러한 용어는 애플리케이션들마다 조금씩 다르게 표현하고 있습니다.
Kafka에서는 Leader와 Follower라고 표현합니다.
•
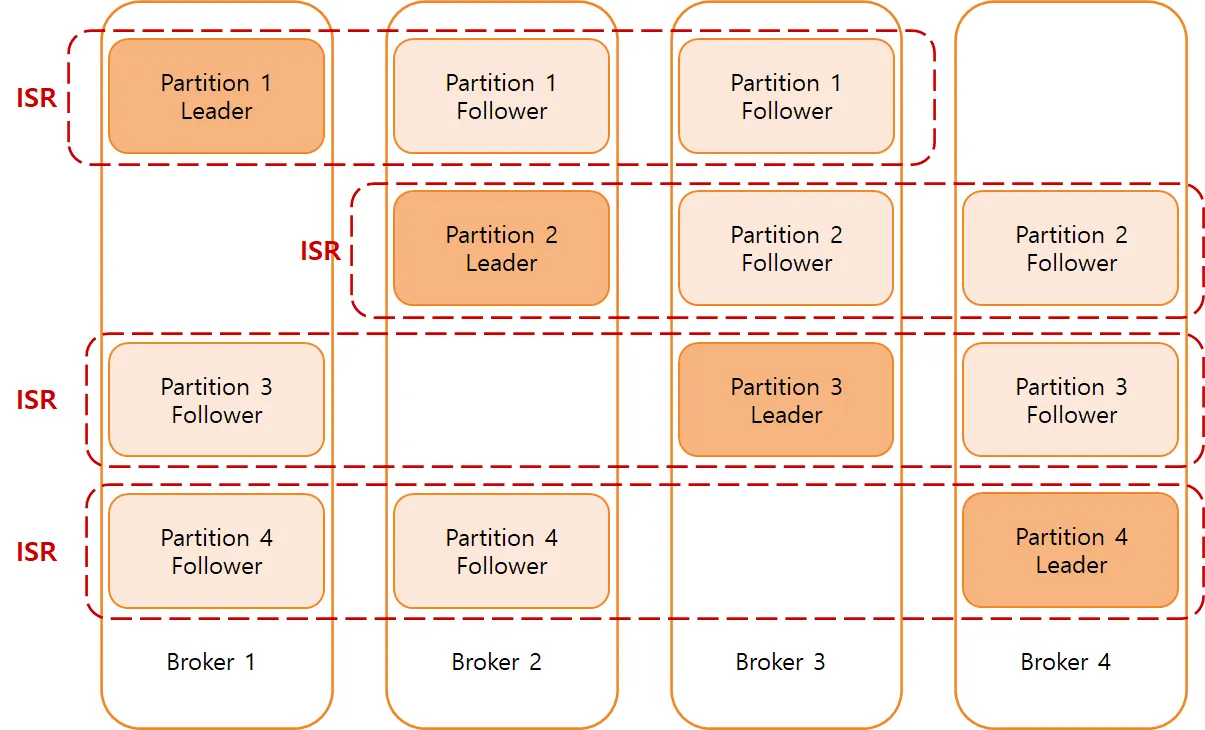
Kafka의 Topic은 1개 이상의 Partition으로 구성되고, 각 Partition은 1개의 Leader replica와 0개 이상의 Follower replica로 구성된다.
◦
Replication factor가 1이라면 Partition은 1개의 Leader replica와 0개의 Follower replica로 이루어진다.
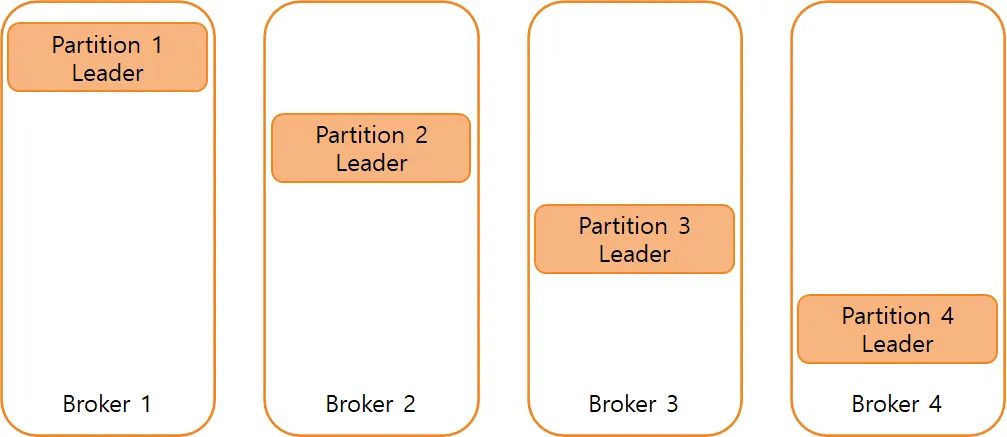
Partition이 4, Replication factor가 1으로 설정된 Topic
•
만약 Replication factor가 3이라면 1개의 Leader replica와 2개의 Follower replica로 이루어진다.
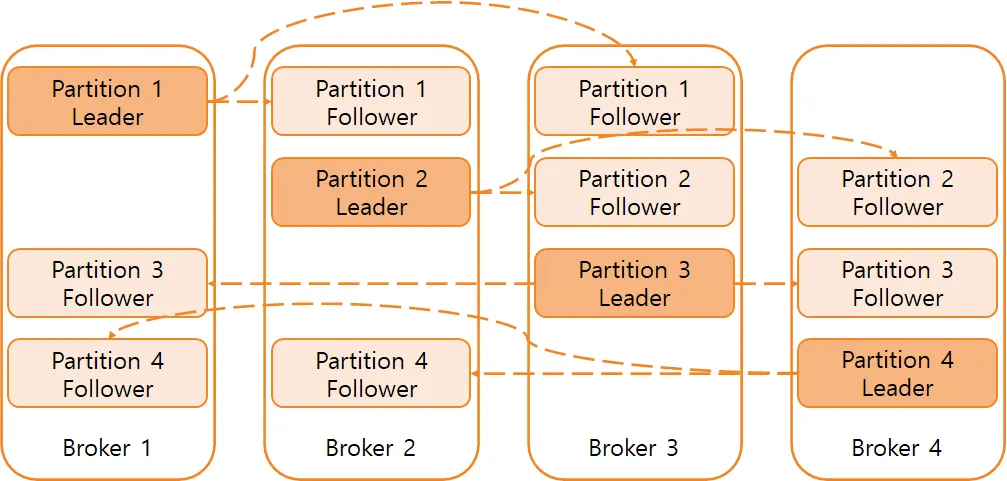
Partition 4, Replication factor가 3으로 설정된 Topic
•
Leader는 리플리케이션중에서 하나가 선정되며 Topic으로 통하는 모든 데이터의 read/write는 오직 Leader를 통해 이루어진다.
◦
각각의 Partition의 Leader만 read/write 가능하기에 Producer은 Leader들에만 메시지를 보내며, Consumer도 Leader들로부터 메시지를 가져온다.
◦
즉, Leader replica는 일관성을 보장하기 위해 모든 Producer와 Consumer의 요청을 처리하며 데이터를 읽고 저장한다.
Failover
•
Follower replica는 Leader replica의 데이터를 복제하여 동일하게 유지하다가 Leader replica가 중단되는 경우 Follower replica 중 하나가 해당 Partition의 새로운 Leader replica로 선출된다.
•
만약 기존 Leader replica에 예상치 못한 문제가 생겨 새로운 Leader replica가 선출되어야 하는 상황이 발생했을 때 제대로 데이터를 복제해 오지 못한 Follower replica가 존재한다면, 해당 개체를 제외한 나머지 Follower replica 중에서 Leader replica를 선출해야 한다.
•
이를 위해서 Kafka에서는 ISR(In Sync Replica)이라는 개념을 도입했다.
ISR (In Sync Replica)
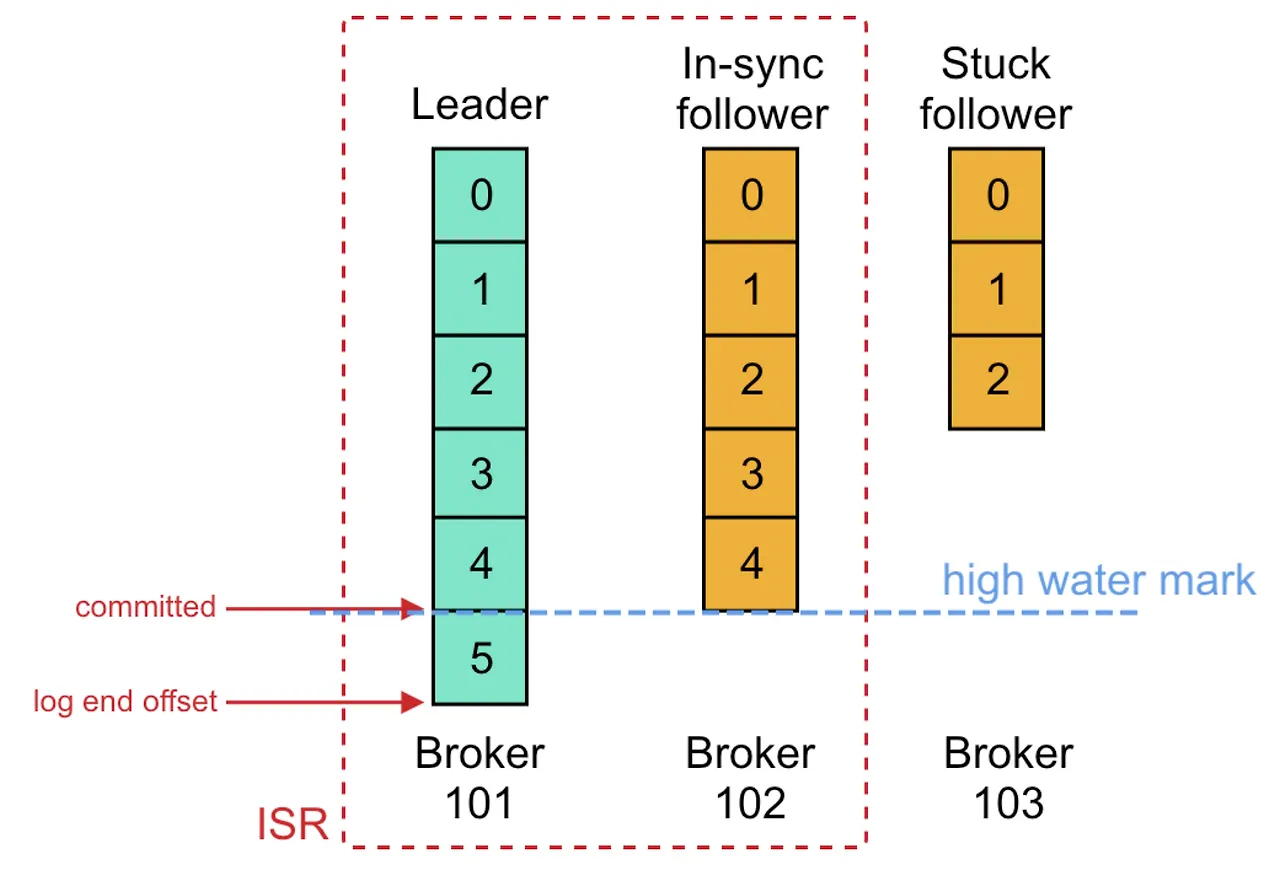
Leader replica와 동기화가 이루어진 Follower replica로 구성된 ISR
•
ISR(In Sync Replica)이란 일종의 Replication Group이라 생각하면 편하다.
◦
이 그룹은 Leader replica와 제대로 동기화가 이루어진 Follower replica들로 구성된다.
•
ISR이라는 논리적인 그룹에 Leader와 Follower는 묶여있으며 ISR 그룹에 속하지 못한 Follower는 새로운 Leader가 될 수 있는 자격이 없다.
•
같은 ISR내의 모든 Follower들은 누구라도 Leader가 될 수 있다.
◦
Leader가 down 되거나, Leader가 있는 브로커가 down 되었을 때, Follower 중 하나가 새로운 Leader가 된다.
ISR가 있어야하는 이유
Follower 역시도 불완전한 상태로 존재할 수 있고 불완전한 Follower가 새로운 Leader가 된다면 데이터의 정합성이나 메시지의 손실과 같은 치명적인 문제가 발생할 수 있기 때문이다.
•
동기화를 하기 위해 Follower replica들은 Fetch 요청을 Leader replica에게 보내고, Leader replica는 그 응답으로 Follower replica들에게 메시지를 전송한다.
•
Fetch 요청에는 Follower replica들이 다음으로 받기 원하는 메시지의 Offset이 포함되며, 항상 수신된 순서대로 처리된다.
◦
Replication Factor 수만큼 전부 메시지를 저장했다면, committed 표시를 하며 마지막 커밋 Offset 위치는 high water mark라고 부른다.
•
log-end-offset은 해당 토픽 파티션에 저장된 데이터의 끝을 나타내며(브로커가 관리함), 파티션에 쓰고 클러스터에 커밋된 마지막 메시지의 Offset입니다.
◦
메시지의 일관성을 유지하기 위해서 커밋된 메시지만 Consumer가 읽어갈 수 있다.
•
Follower replica가 일정 시간 이상 Fetch 요청을 하지 않거나, 요청은 했지만 시간 안에 Leader replica의 마지막 Offset의 메시지를 복제하지 못한다면 동기화에 실패한 것으로 간주하여 Leader replica는 해당 Follower replica를 ISR에서 제거한다.
◦
해당 시간은 브로커 설정 파일의 replica.lag.time.max.ms 값으로 설정할 수 있다.
Leader의 관점
•
브로커가 down 되는 경우 ISR 내 Follower는 Leader로부터 데이터를 가져오지 못하게 되고, 이러한 상황이 일정 시간 지속되면서 Leader는 해당 Follower가 뒤쳐졌기 때문에 해당 Follower에게 Leader를 넘길 수 없다고 판단하여, 해당 Follower를 제외시키게 되고 ISR이 축소되는 것이다.
◦
즉, Leader는 ISR 내 Follower들을 감시하고 자신보다 뒤처지는 Follower는 Leader가 될 자격이 없다고 판단하여, ISR에서 강제로 제외시킨다.
Follower의 관점
•
ISR 내 Follower는 누구라도 Leader가 될 수 있다는 조건이 있기 때문에 Follower는 Leader와 동일한 데이터를 유지하는 것이 매우 중요하다.
•
따라서 Follower는 Leader를 계속 바라보면서 Consumer들이 kafka에서 데이터를 pull로 가져는 것과 동일한 방법으로 주기적으로 데이터를 pull한다.
•
매우 짧은 주기마다 Leader가 새로운 데이터를 받았는지 계속 체크하면서 Leader와 동기화한다.
ISR 요약
•
Leader : Follower 중에서 자신보다 일정기간 동안 뒤쳐지면 Leader가 될 자격이 없다고 판단하여 뒤쳐지는 Follower를 ISR에서 제외시킨다.
•
Follower : Leader와 동일한 데이터 내용을 유지하기 위해서 짧은 주기로 Leader로부터 데이터를 가져온다.
•
Leader가 down되면 같은 ISR내 Follower중 하나가 Leader가 된다.
Partition
•
하나의 토픽이 한 번에 처리할 수 있는 한계를 높이기 위해 토픽 하나를 여러 개로 나눠 병렬 처리가 가능하게 만든 것을 파티션(Partition)이라 한다.
•
파티션을 통해 토픽을 여러 개로 나누면 분산 처리가 가능하며, 나뉜 파티션 수만큼 컨슈머(consumer)를 연결할 수 있다. 토픽과 파티션의 관계를 그림으로 나타내면 아래와 같다.
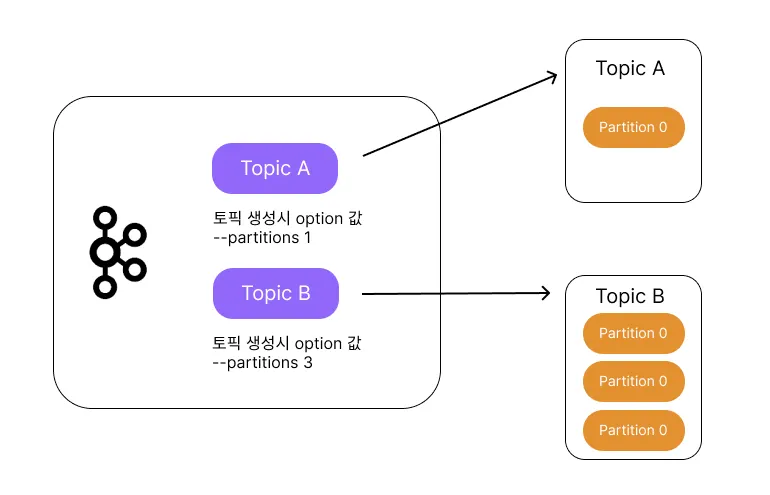
파티션 번호는 0번부터 시작한다.
•
파티션은 초기 생성후 그 이상으로 늘릴 수는 있지만 반대로 한번 늘린 파티션은 줄일 수 없다.
•
파티션수를 2, 4로 작게 생성한 뒤, 메시지 처리량이나 Consumer의 LAG(Producer가 보낸 메시지 수 - Consumer가 가져간 메시지 수) 등을 등을 모니터링하면서 조금씩 늘려가는 방법이 좋다.
◦
LAG는 Consumer의 current-offset과 브로커의 log-end-offset 간의 차이로 만들어진다.
▪
예를들어 Producer가 5개의 메시지를 Kafka로 전송했는데 Consumer는 4개의 메시지만 가져갔다면 Consumer LAG는 1이다.
◦
만약 Consumer가 모든 메시지를 가져갔다면 Consumer LAG는 0이다.
◦
즉 LAG 지표를 활용하면 Consumer에 지연이 있는 상황인지 확인할 수 있고, 파티션 수를 결정하기 위한 근거로 사용할 수 있다.
Segment
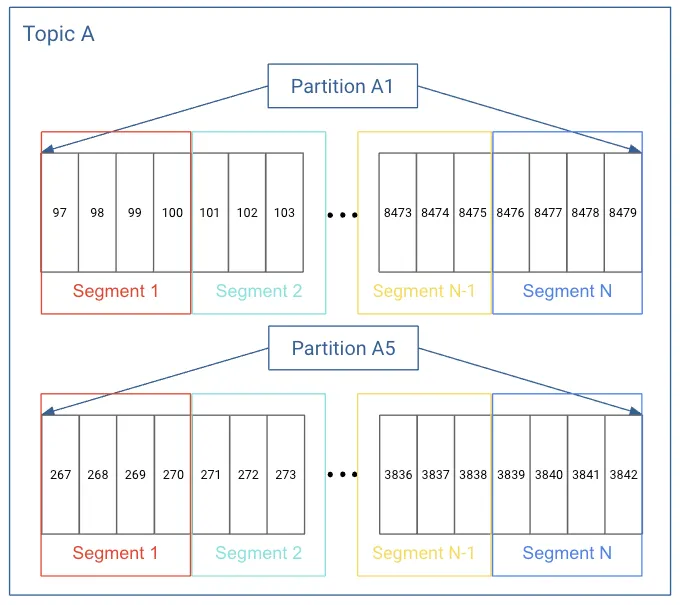
•
각 Partition 마다 n개의 Segment들이 존재한다.
•
Producer에 의해서 브로커로 전송된 메시지는 Topic의 Partition에 저장되며, 각 메시지들은 Segment라는 로그 파일의 형태로 브로커의 로컬 디스크에 저장된다.
◦
Kafka 서버로 접속한 후, 리눅스 명령어를 통해 /kafka/kafka-logs-${hashvalue}디렉토리 경로로 들어가면 메시지를 보낸 Topic에 대한 디렉토리도 존재하는 것을 볼 수 있다
◦
/kafka/kafka-logs-{hashvalue}/{topic}-{partition number}
▪
Topic 생성 시 Partition 값만큼 생성된다. (0부터 시작한다)
▪
ex) test-0 , test-1
◦
특정/{topic}-{partition number} 디렉토리로 들어가게 되면 4가지 파일이 존재한다.
▪
00000000000000000000.index : Log Segment에 저장된 위치와 offset 정보를 기록한다.
▪
00000000000000000000.log : 실제 메시지들이 저장되는 파일이다.
▪
00000000000000000000.timeindex : 메시지의 타임스탬프를 기록하는 파일이다.
▪
leader-epoch-checkpoint : kafka에서 컨트롤러가 이전에 할당한 Leader의 수를 나타낸다.
•
새 Leader를 선택하고 leader-epoch를 1씩 증가시키며 모든 Replicas와 공유한다.
◦
Producer가 보낸 메시지만 확인하기 위해 먼저 0000...00.log 파일만 사용할 것이다. 이 파일을 확인하기 위해서는 kafka가 제공하는 kafka-dump-log.sh를 사용하면 된다.
◦
이를 통해 Producer가 전송한 메시지가 브로커의 로컬 디스크에 안전하게 저장되어 있다는 것을 알 수 있다.
cd /kafka/kafka-logs-6103e24753b5/test-0
kafka-dump-log.sh --print-data-log --files /kafka/kafka-logs-{hashvalue}/{topic}-{partition number}/00000000000000000000.log
Shell
복사
Segment에서 메시지를 읽어오는 흐름
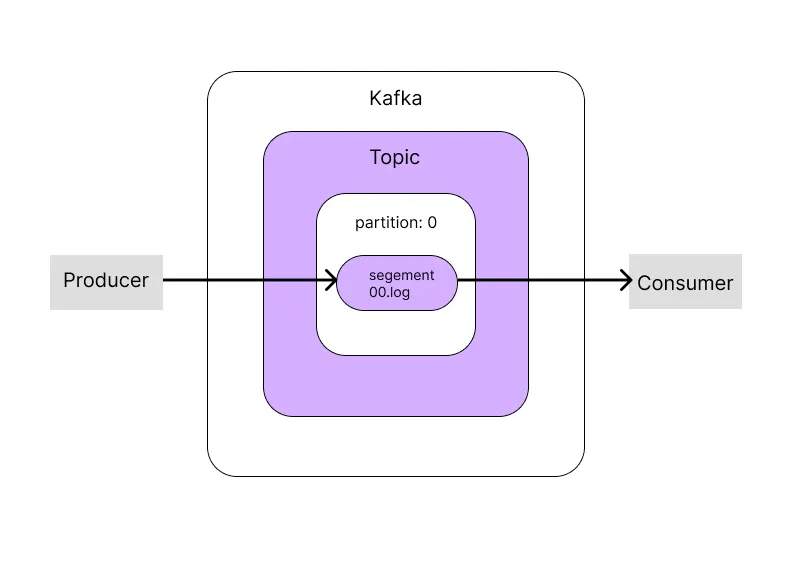
1.
Producer는 kafka의 A라는 Topic으로 메시지를 전달한다.
2.
A Topic은 Partition이 하나여서 0이며 Producer로부터 받은 메시지를 Partition의 Segment .log파일에 저장한다.
3.
브로커의 Segment log file에 저장된 메시지는 Consumer가 읽어 갈 수 있다.
4.
Consumer는 A Topic을 pull 해서 해당 Topic안의 Partition-0의 segment log file에서 메시지를 가져온다.
Kafka 옵션
Popular Configuration
acks=all and min.insync.replicas=2 is the most popular option for data durability and availability and allows you to withstand at most the loss of one Kafka broker
https://www.conduktor.io/kafka/kafka-topic-configuration-min-insync-replicas/#Kafka-Topic-Durability-&-Availability-1
아파치 카프카 문서에서는 손실 없는 메세지 전송을 위한 조건으로 프로듀서는 acks=all, 브로커의 min.insync.replicas=2, Topic의 Replication Factor = 3으로 권장하고 있다.
ACKS
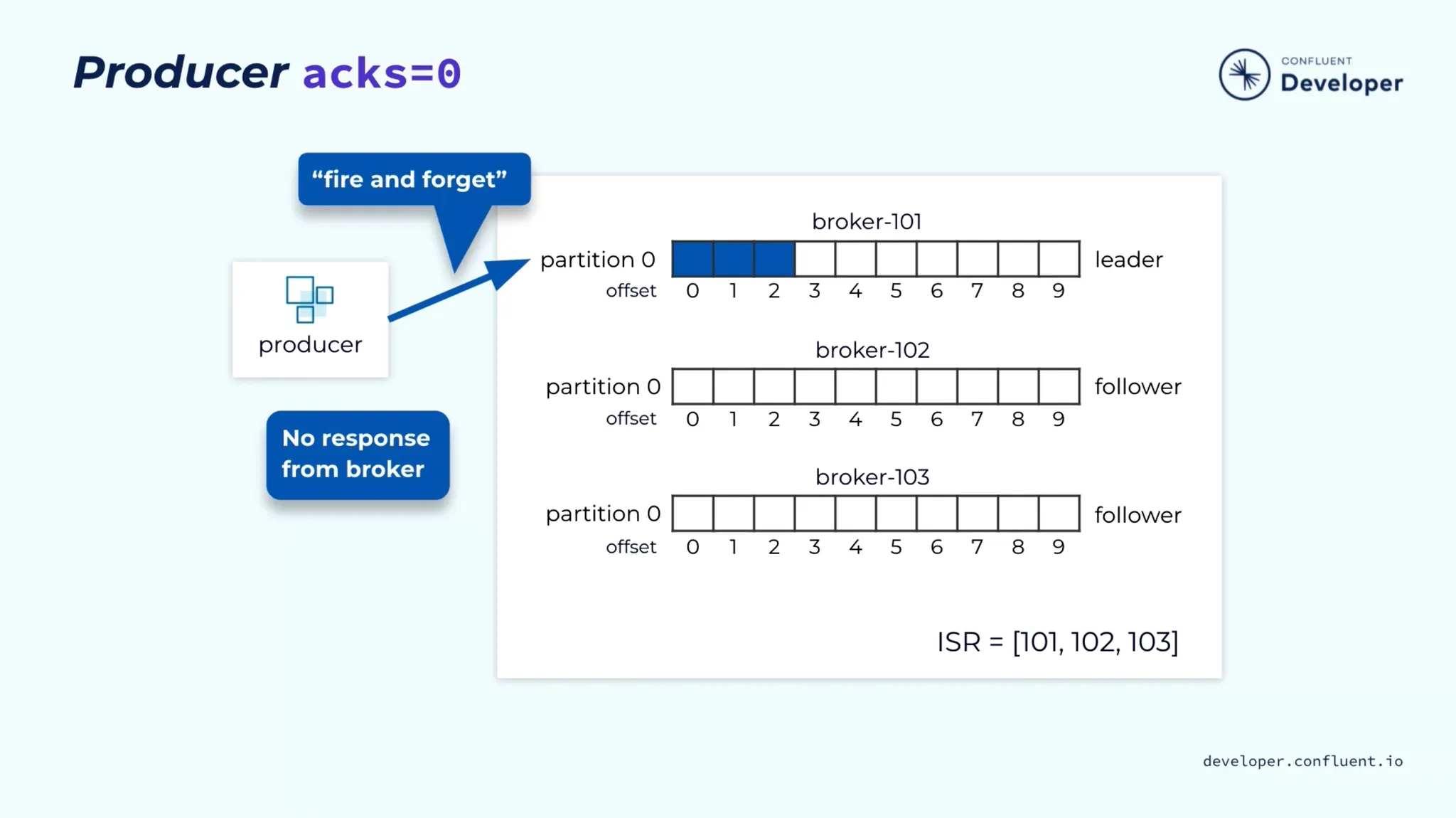
•
acks=0로 설정할 경우 Producer가 메시지가 수신되었음을 확인하는 어떠한 통지(ACK)도 기다리지 않는다.
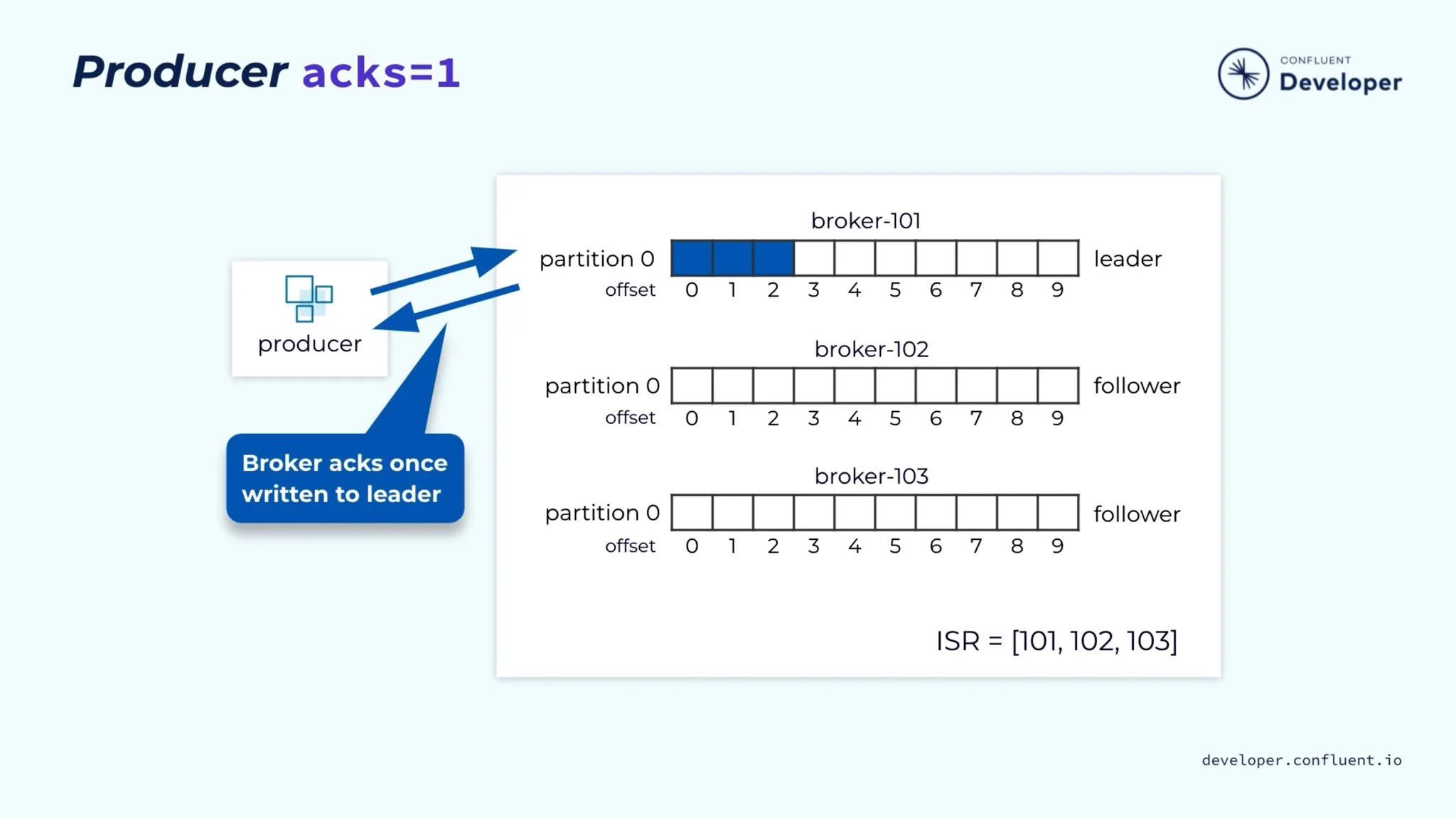
•
acks=1로 설정할 경우 Leader에만 메시지가 정상적으로 저장되면 응답(ACK)한다.
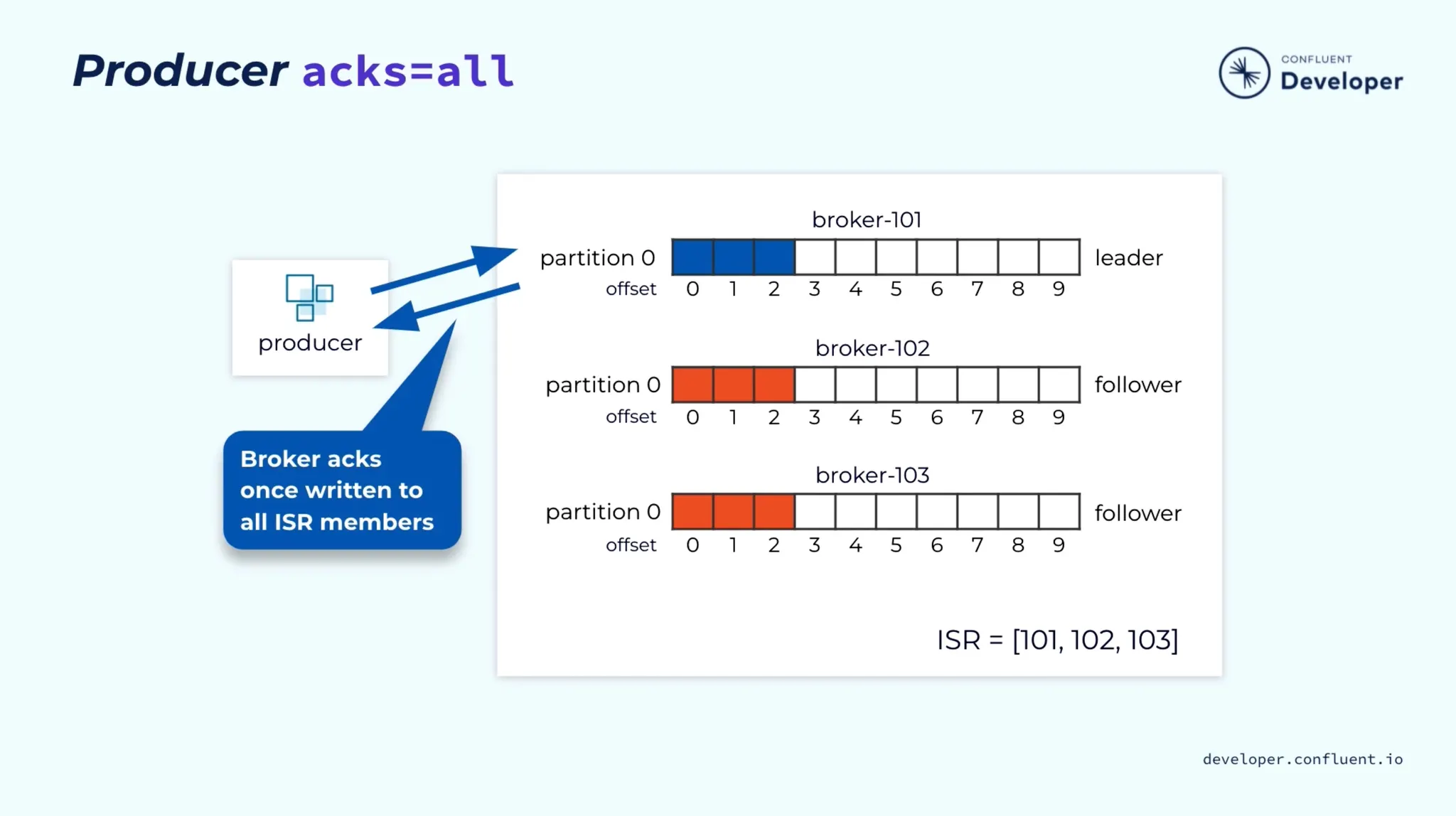
•
acks=all로 설정할 경우 Leader뿐만 아니라 모든 ISR(In-Sync Replicas)에 메시지가 저장되어야 응답(ACK)한다.
◦
그렇기에 acks=1보다 약 2.5배정도 느리다, 대신 더 높은 guarantee를 가진다.
idempotence
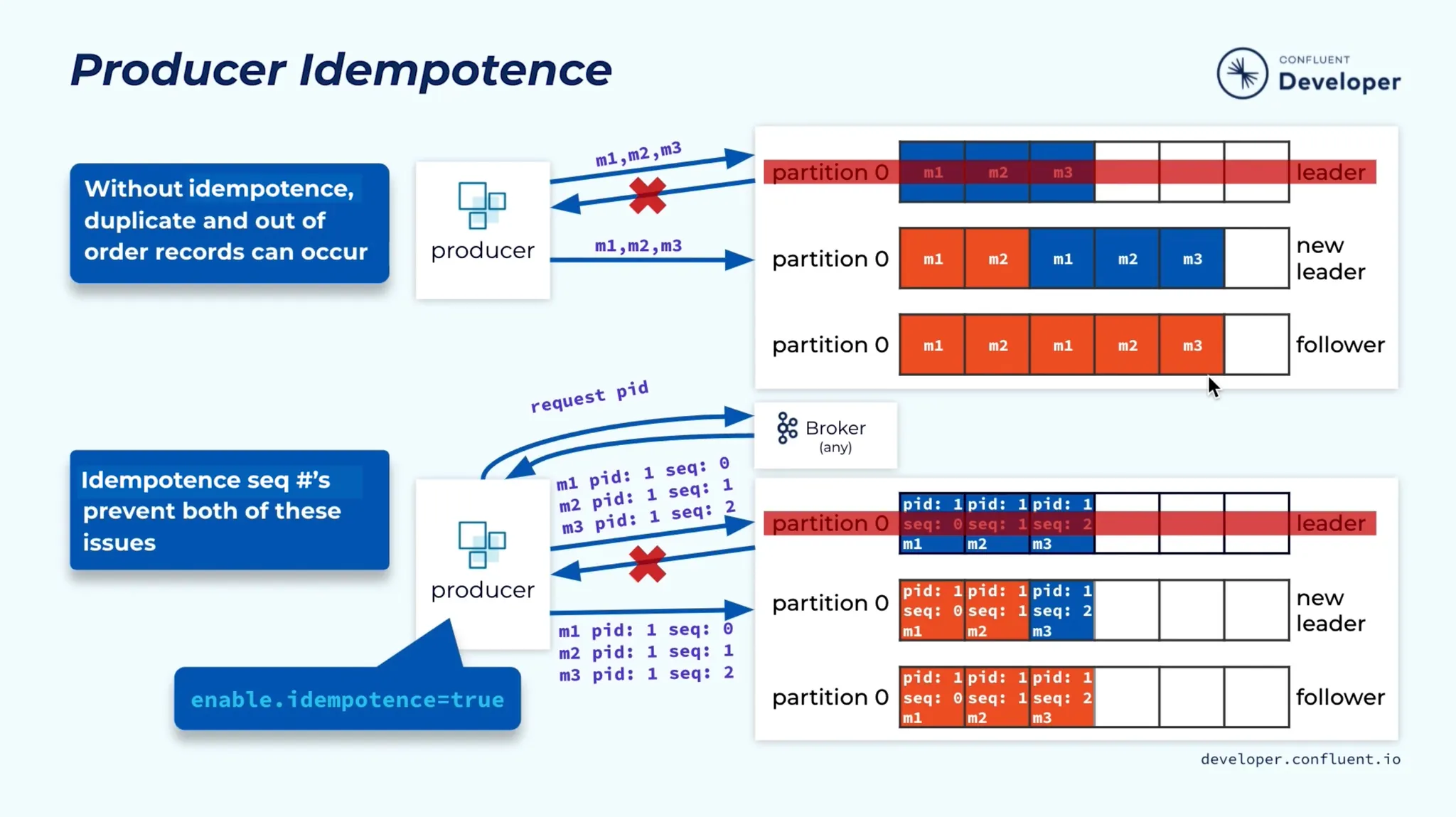
•
Kafka 0.11.0.0 버전부터, Producer는 메시지 전달을 구성하기 위한 멱등(idempotence) 옵션 enable.idempotence을 제공한다.
•
멱등 옵션은 메시지를 재전송해도 로그에 중복 항목이 발생하지 않고 로그 순서가 유지되는 것을 보장한다.
◦
중복으로 전송된 메시지를 무시한다.
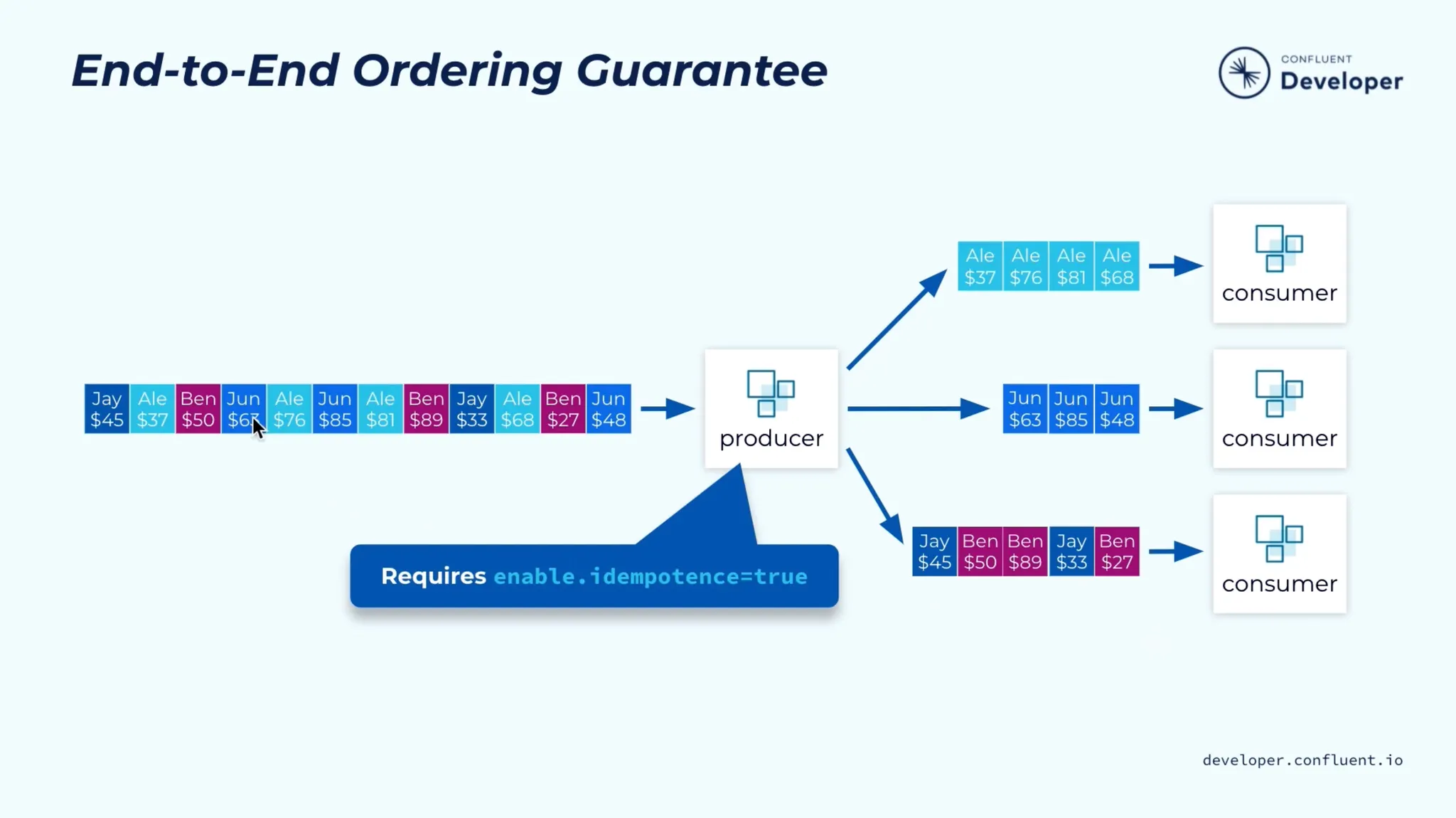
•
이를 위해 Broker는 각 Producer에게 ID(pid)를 할당하고 프로듀서가 모든 메시지와 함께 보내는 일련 번호(seq)를 사용하여 메시지를 중복 제거한다.
min.insync.replicas
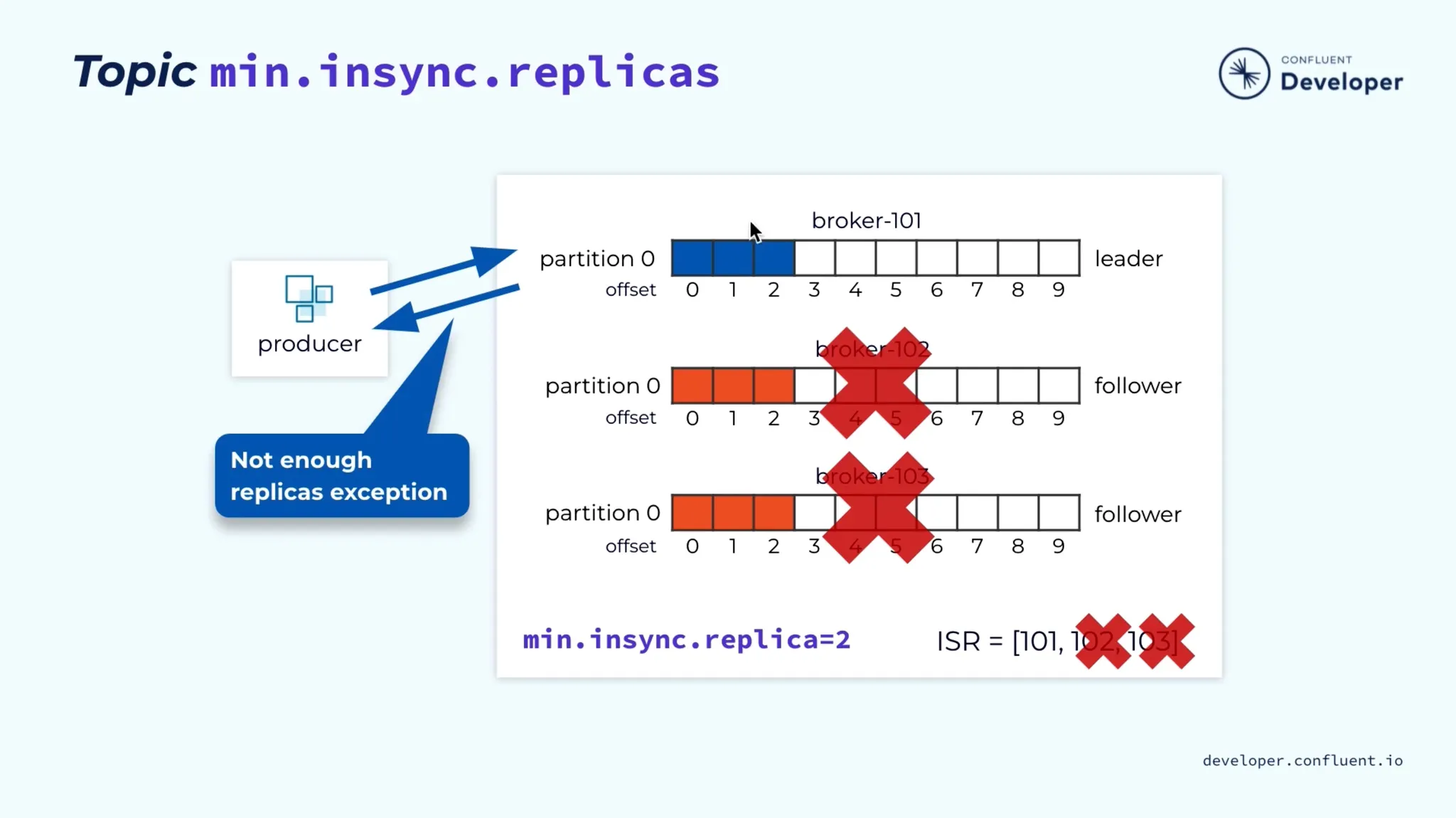
•
메시지를 전송할 때 최소 N개의 Replicas에 복제되어야 성공으로 간주한다.
•
min.insync.replicas=1 (기본값)
◦
해당 토픽은 최소한 1개의 파티션이 ISR(리더를 포함)로 있어야 하며, 따라서 두 개의 브로커가 다운되더라도 견딜 수 있다.
•
min.insync.replicas=2
◦
해당 토픽은 최소한 2개의 ISR이 있어야 하며, 따라서 최대 하나의 브로커가 다운될 수 있다
▪
Replication Factor가 3인 경우
◦
또한, 모든 쓰기 작업에 대해 데이터가 최소 두 번 기록된다는 보장이 있습니다.
•
min.insync.replicas=3
◦
Replication Factor가 3인 경우에는 큰 의미가 없으며, 어떤 브로커도 다운될 수 없습니다.
•
요약하면, acks=all과 replication.factor=N 및 min.insync.replicas=M인 경우, 토픽 가용성을 위해 N-M개의 브로커가 다운되는 것을 견딜 수 있다.
메시지 전송 전략
Kafka Message Delivery Semantics
No gurantee | 0~N개의 메시지 | 메시지 전송에 대해 보장하지 않는다.
메시지가 유실되거나 한번 또는 여러번 동일한 메시지를 처리할 수 있다. |
At most once | 최대 1개의 메시지 | 메시지는 단 한 번만 전송하며, 유실될 수 있고 재전송하지 않는다. |
At least once | 최소 1개의 메시지 | 메시지는 절대 유실되지 않고 최소 한 번 전송이 완료된다. 하지만 재전송이 일어날 수 있다. |
Exactly once | 정확히 1개의 메시지 | 메시지는 유실되지 않고 단 한 번 전송이 완료된다. 재전송이 일어나지 않는다.
대부분의 사용자가 기대하는 보장 수준이다. |
Producer
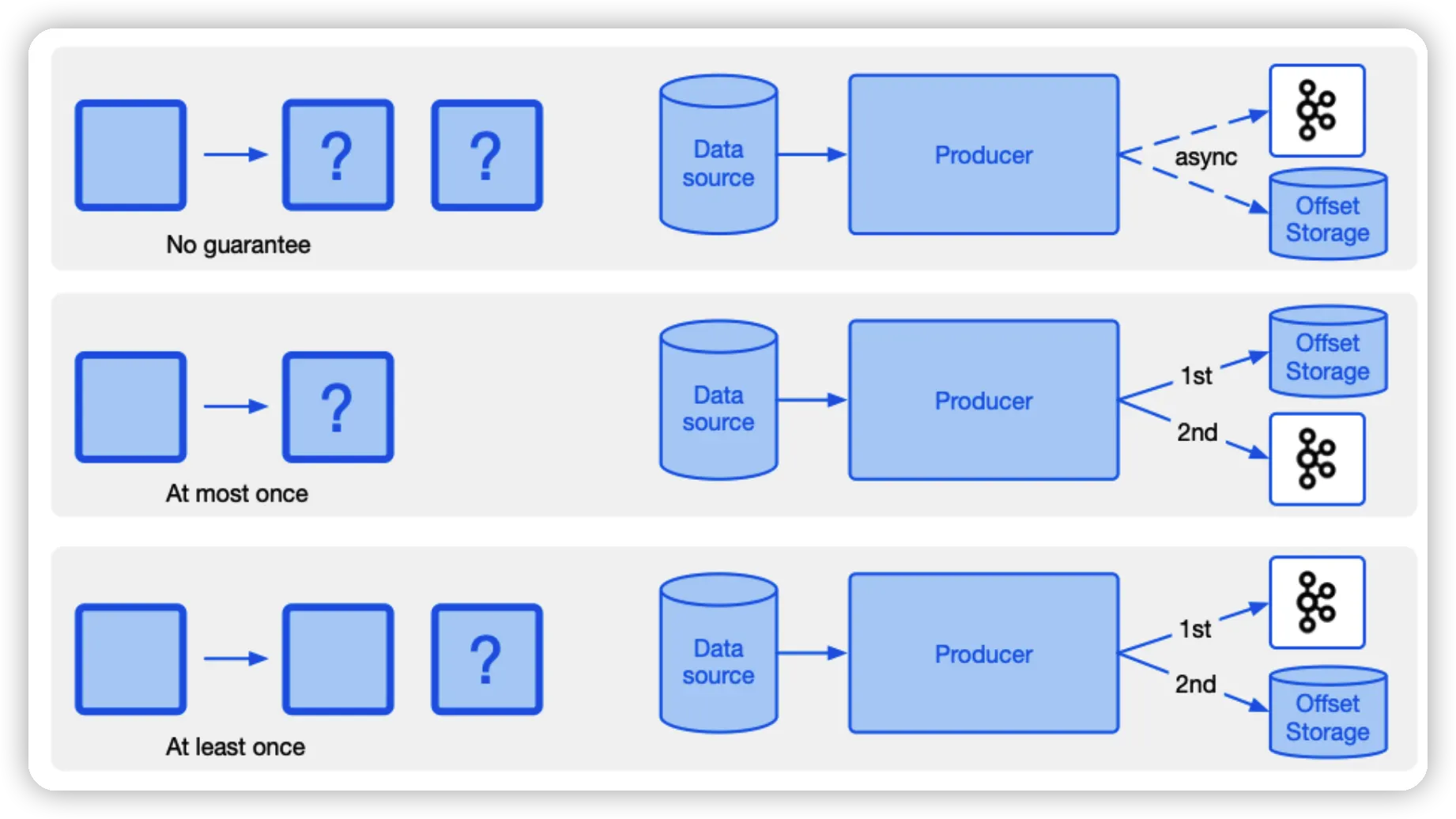
•
Producer에서는 주로 Broker와 Offset Storage에 어떻게 저장할 것인지에 따라 정책이 나뉜다.
At most once
•
가장 낮은 지연 시간을 위해 메시지를 비동기적으로 "보내고 잊는" 방식으로 전송할 수 있다. (acks=0)
•
또는 더 많은 지연 시간을 감수하면서도 메시지 손실의 위험을 줄이기 위해, Producer가 Leader Broker로부터의 확인을 기다릴 수 있다. (acks=1)
◦
Leader Broker가 다운되거나 네트워크 장애 등과 같은 상황에서 굳이 전송하지 않음으로서 메시지 손실 감소.
•
어느 경우이든 메시지는 한 번만 전송하며, 시스템에 장애가 발생하면 메시지가 손실될 수 있으며, 재전송하지 않는다.
•
따라서 메시지가 다소 유실되어도 괜찮고 대신 더 높은 성능을 요구하는 상황이라면 At most once를 고려해볼만 하다.
At least once
•
Producer가 메시지가 commit되었음을 나타내는 응답(ACK)을 받지 못한 경우, 메시지를 재전송한다. (acks=all)
◦
메시지 재전송 중에 원본 요청이 성공했다면 log에 다시 기록될 수 있다. (중복 메시지 발생)
◦
다만 중복 메시지는 위에서 서술한 멱등(Idempotence) 옵션을 통해 방지 할 수 있다.
Exactly once
•
Kafka 0.11.0.0 버전부터 Producer는 트랜잭션 전달을 사용할 수 있다.
◦
이는 Producer가 여러 토픽에 메시지를 보내는 과정을 트랜잭션화하여 전부 성공하거나 혹은 모두 실패하는 원자적(atomicity) 실행을 보장할 수 있게 되었고, 메시지를 다시 보낼 경우 멱등성을 통해 중복을 피한다.
•
이는 높은 지연시간을 수반하지만 가장 높은 내구성을 제공한다.
•
트랜잭션 보장을 활성화하기 위해서는 Consumer도 적절히 구성되어야 한다.
Consumer
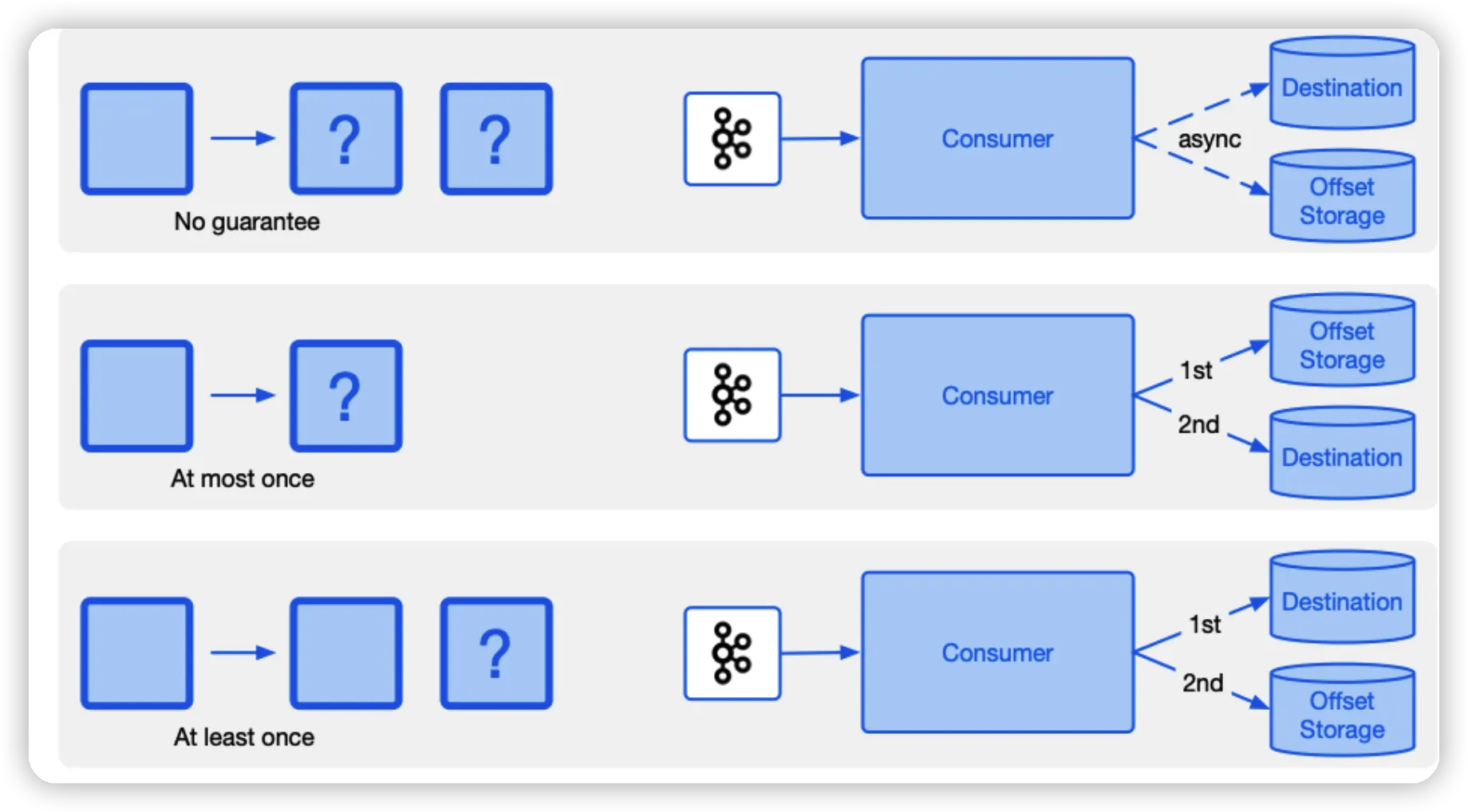
Kafka에서는 Consumer가 메시지를 어디까지 읽었는지에 대한 정보 offset(위치)을 내부 토픽인 __consumer_offsets에 기록한다.
At most once
•
Consumer는 메시지를 읽고 offset을 기록한 다음에 메시지를 처리한다.
•
만약 Consumer가 offset을 기록한 후, 메시지 처리 결과를 저장하기 전에 장애가 발생한다면, 처리를 이어받은 또 다른 Consumer는 저장된 위치부터 시작하고 그 이전의 메시지를 처리되지 않는다.
•
이는 Consumer에 대한 최대 한 번의 의미를 가지며, 실패 시 메시지가 처리되지 않을 수 있다.
At least once
•
Consumer가 메시지를 읽고 메시지를 처리한 다음에 offset를 기록한다.
•
Consumer가 메시지를 처리한 후, offset를 기록하기 전에 장애가 발생한다면, 처리를 이어받는 또 다른 Consumer는 offset이 변경되지 않았기에 일부 메시지를 두 번 처리할 수 있다.
◦
이 경우 메시지에 primary key를 할당하여 멱등성을 가지도록 할 수 있다. (메시지 중복 방지)
Exactly once
•
Kafka 0.11.0.0 버전에서 추가된 트랜잭션 기능을 활용하여 Exactly once을 달성한다.
•
Consumer는 "메시지 처리"와 "offset 기록"하기 총 2가지 일을 해내야 한다.
•
Exactly Once를 보장하기 위해서는 이 2개의 작업을 하나의 트랜잭션으로 묶어서 둘 중 하나가 실패한 경우 전부 롤백되어야 하고 두 가지가 모두 성공한 경우에만 성공으로 처리할 수 있다.
•
isolation_level 속성을 사용하여 토픽이 다른 Consumer에게 보이는지 지정할 수 있다.
◦
기본 격리 수준인 read_uncommitted에서는 중단된 트랜잭션의 메시지까지도 Consumer에게 보인다.
◦
read_committed에서 Consumer는 커밋된 트랜잭션의 메시지만 읽는다.
Exactly once 적용 방법
•
Consumer가 메시지를 읽고, offset을 commit하는 방법은 2가지가 있다.
1.
enable.auto.commit = true
•
일정 주기(auto.commit.interval.ms, default 5초)마다 가져온 record의 offset을 commit하는 전략
2.
enable.auto.commit = false
•
Application에서 수동으로 commit 하는 전략
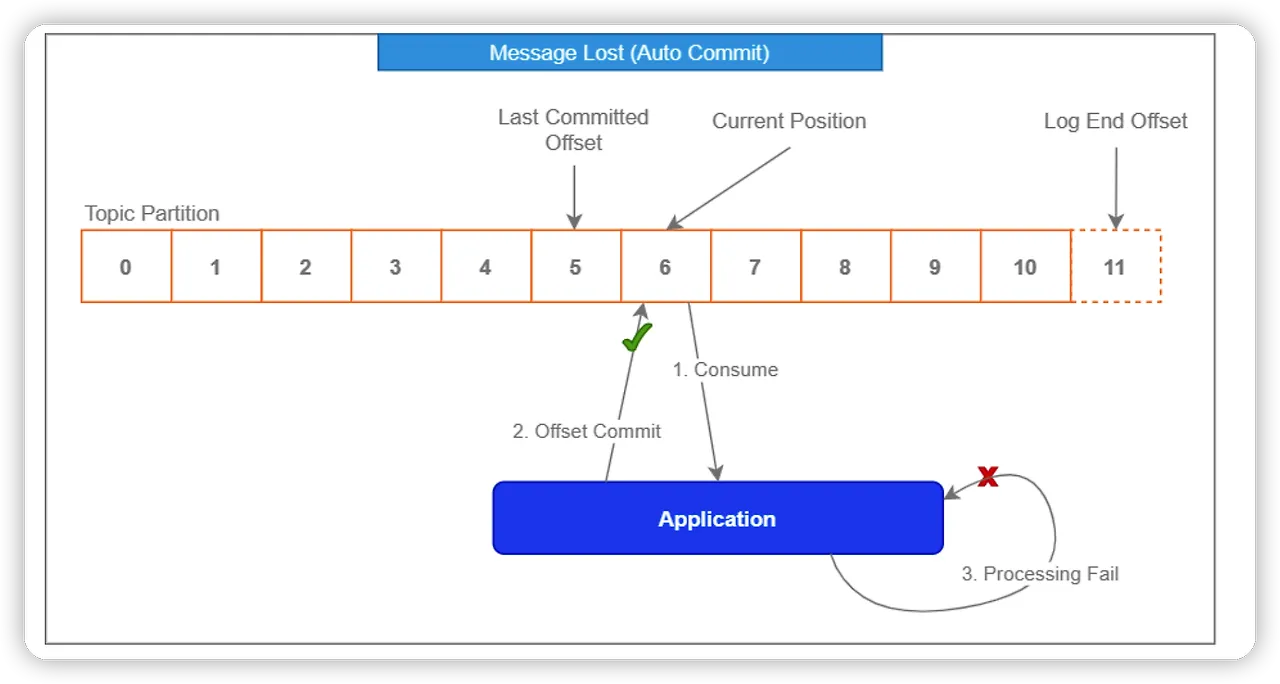
Auto commit
•
auto.commit = true 의 경우에는 자동으로 commit 하기 때문에 아래와 같은 메세지 유실이 발생할 수 있다.