

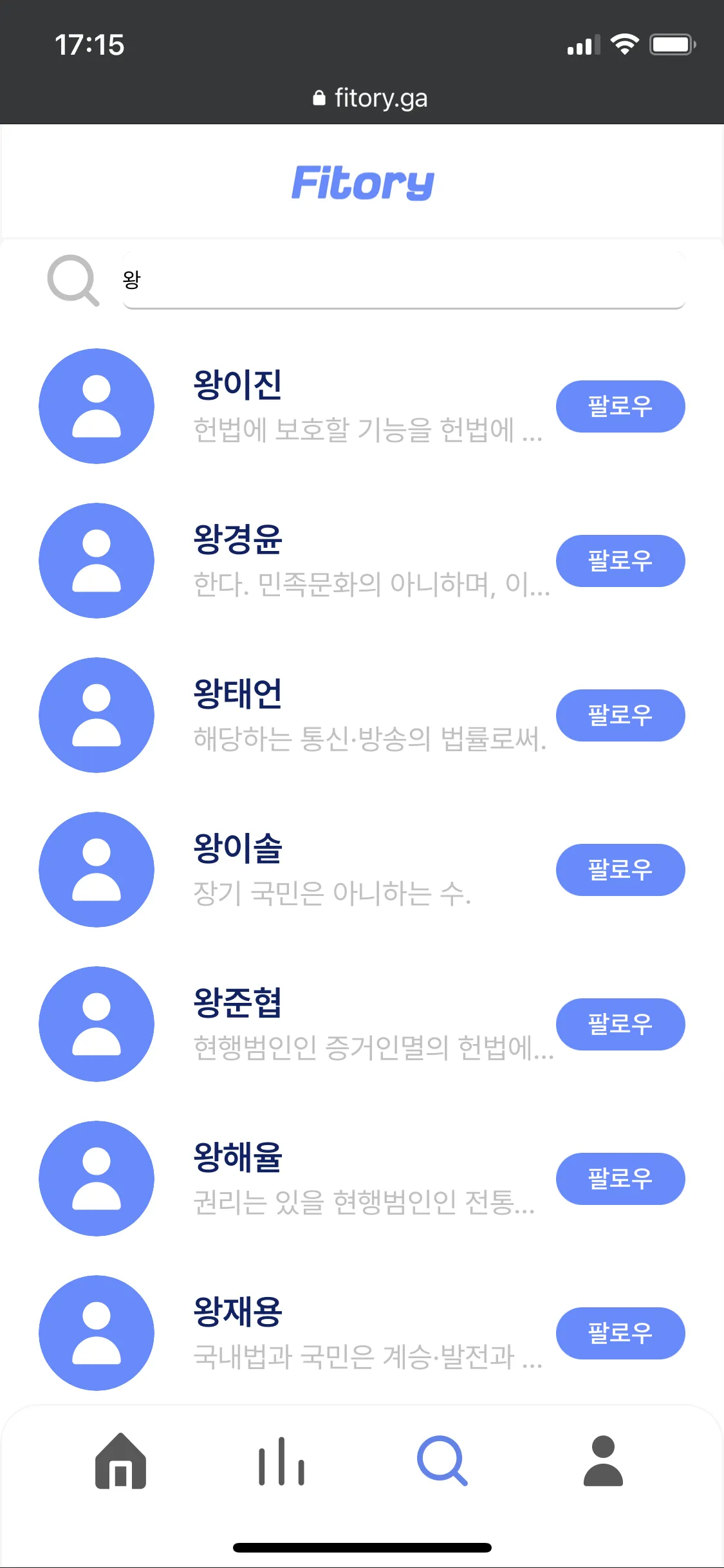
유저 검색 개선
기존 방식
•
검색 페이지에 들어올 때 마다 모든 유저의 [ id, name, introduce, profile_image ]를 가져와 클라이언트로 전송한다.
const userProfileList = await this.userRepository
.createQueryBuilder("user")
.select("user.user_id", "user_id")
.addSelect("user.name", "name")
.addSelect("user.introduce", "introduce")
.addSelect("user.profile_image", "profile_image")
.getRawMany();
TypeScript
복사
•
클라이언트측에서는 검색을 할 때 해당 검색어를 리스트의 name에서 찾아 일치하는 유저들을 보여준다.
문제점
•
검색 페이지에 들어올 때 모든 유저의 정보를 가져오는게 너무 오래 걸린다.
◦
심지어 이걸 매번 검색 페이지에 들어올 때 마다 받아온다.
•
검색 페이지에 들어오면 로딩 시간이 필요한 상황이라 사용자 입장에서 사용했을 때 심각한 불편을 느꼈다.
•
개발자 도구에서 네트워크를 확인해보니 모든 유저 정보를 가져오는데 대략 120ms이 걸리는 것을 볼 수 있으며, 다른 API와 비교했을 때 대략 4~6배 느린것을 확인할 수 있다.
◦
현재 대략 5000명 가짜 유저를 mock 데이터 생성기를 통해 DB에 삽입 된 상태이다.
◦
즉, 5000명의 [ id, name, introduce, profile_image ]를 갖고오는데 120ms이 걸린다.
◦
만약 서비스 이용자가 1만 명, 10만 명일 경우 매우 느릴 것으로 보인다.

고민
•
먼저 사용자 입장에서 검색 기능의 이용 빈도를 생각 했을 때 과연 얼마나 사용할까를 생각해봤다.
•
인스타를 생각해봤을 때 다른 사람을 팔로잉할 때 주로 검색 기능을 사용한다.
•
그 때문에 다른 기능에 비해 상대적으로 낮은 이용 빈도가 예상된다.
◦
또한 검색 페이지에 들어온다고 해서 무조건 검색을 하는 것도 아니다.
•
그래서 굳이 모든 유저 정보를 가져올 필요 없이 사용자가 검색어(이름)를 입력할 경우 해당 검색어에 해당되는 유저 정보들만 가져와서 보여주면 되지 않을까라는 생각을 했다.
개선 방법
검색 기능
•
수 천, 수 만 명의 유저들 중에서 사용자가 다른 유저의 정보를 찾고, 원하는 유저를 검색해 팔로잉을 하는 검색 기능은 우리 서비스(Fitory)에서 필수적인 기능이다.
•
제한된 프로젝트 개발 기간 동안 적절한 성능을 내는 검색 엔진을 개발하기 앞서 우리가 고려한 부분은 다음과 같다.
1.
프로젝트 개발 기간이 제한적이다. → 러닝 커브가 있는 새로운 기술 스택을 사용하지 않고, 기존 기술 스택인 MySQL을 사용한다.
2.
대용량 데이터에서 문자열 검색을 처리하는데 준수한 성능을 보여준다.
LIKE
•
데이터베이스에서 문자열을 찾는 쿼리를 날릴 때 가장 먼저 떠오르는 것은 MySQL의 LIKE이다. 초기에는 LIKE를 이용한 쿼리를 개발하고, 추후에는 조회 시에 인덱스를 이용해서 성능을 개선할려 했다.
const userProfileList = await this.userRepository
.createQueryBuilder("user")
.select("user.user_id", "user_id")
.addSelect("user.name", "name")
.addSelect("user.introduce", "introduce")
.addSelect("user.profile_image", "profile_image")
.where("user.name like :name", { name: `%${userName}%`})
.getRawMany();
TypeScript
복사
•
그러나 알아본 결과 MySQL의 LIKE는 와일드카드(%)를 사용할 때 항상 인덱스를 이용하는 것이 아니다.
SELECT ... FROM ... WHERE keyword LIKE 'A%';
SQL
복사
◦
위와 같이 와일드카드가 키워드의 우측에만 있는 경우에는 인덱스를 이용할 수 있어서 Index Range Scan으로 검색한다.
SELECT ... FROM ... WHERE keyword LIKE '%A';
SELECT ... FROM ... WHERE keyword LIKE '%A%';
SQL
복사
◦
반면에 위와 같이 와일드카드가 키워드의 좌측에 붙은 경우에는 어떤 문자로 시작하는지 알 수 없기 때문에 Full Table Scan으로 검색한다.
•
즉, 제한적으로만 인덱스를 이용할 수 있게 되어서 좋은 선택지가 아니라고 생각했다.
FullText Search
•
MySQL에서는 문자열 검색을 위해 LIKE 외에 FullText Search를 제공한다.
•
FullText Search는 단어나 구문에 대한 검색을 지원하고자 제공되는 방식이다.
•
검색하고자 하는 column에 FullText Index를 설정해주면, 문자열이 정해진 방법으로 분리되어 인덱스를 생성하고, 이를 빠르게 검색할 수 있다.
•
검색 키워드와 관련성이 높은 순으로 정렬할 수 있고, 추가적인 검색 규칙을 적용할 수 있다.
•
우리(Fitory)는 위와 같은 이유들로 LIKE 대신에 FullText Search를 이용해 검색 기능을 제공하기로 결정했다.
FullText Index
•
FullText Search에서 인덱스를 생성하는 방법은 여러가지 있다.
•
인덱스는 파서가 문자열을 토크나이징한 후에 생성하게 된다. 이런 역할을 수행하는 파서가 여러가지 있지만 여기서는 두 가지만 다뤄본다.
•
Built-In Parser
◦
Built-In Parser는 stopword(구분자)를 기준으로 키워드를 추출하는 방식이다. 공백이나 문장 기호 혹은 사용자가 지정한 특정 단어를 기준으로 토크나이징하게 된다.
◦
예를 들어서, 구분자가 공백이라면 문장이 다음과 같이 쪼개집니다.
왕승재는 집에서 개발을 한다 -> 왕승재는 / 집에서 / 개발을 / 한다
우리가 만든 운동기록서비스 -> 우리가 / 만든 / 운동기록서비스
Plain Text
복사
◦
위와 같은 방식으로 토크나이징 되어 있다면 “승재는” 혹은 “서비스” 와 같은 검색 키워드로는 위 문장을 검색할 수 없다.
◦
FullText Search는 토큰과 검색 키워드가 전부 일치하거나 전방(prefix) 일치한 경우에만 결과를 가져오기 때문이다.
•
N-gram Parser
◦
위와 같은 문제를 해결해주는 파서도 존재한다. N-gram Parser는 MySQL에서 기본적으로 제공하기 때문에 FullText Index를 설정해줄 때 옵션으로 지정해주기만 하면 사용할 수 있다.
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title,body) WITH PARSER ngram;
# OR
CREATE FULLTEXT INDEX ft_index ON articles (title,body) WITH PARSER ngram;
SQL
복사
◦
N-gram 파서는 지정된 토큰 사이즈를 기준으로 키워드를 추출합니다.
◦
예를 들어서, 토큰 사이즈가 2 라면 문장이 다음과 같이 쪼개집니다.
왕승재는 집에서 개발을 한다
-> 왕승 / 승재 / 재는 / 는집 / 집에 / 에서 / 서개 / 개발 / 발을 / 을한 / 한다
우리가 만든 운동기록서비스
-> 우리 / 리가 / 가만 / 만든 / 든운 / 운동 / 동기 / 기록 / 록서 / 서비 / 비스
Plain Text
복사
◦
위와 같은 방식으로 토크나이징 되어 있다면 “승재는” 는 “승재 / 재는” 로 검색되고, “서비스” 는 “서비 / 비스” 로 검색됩니다. 각각 두 개 씩 일치하기 때문에 Built-In Parser에서는 검색되지 않던 내용들이 검색되게 된다.
Space Handling : N-gram 파서는 공백이 포함된 경우 키워드로 추출하지 않는다.
MATCH (…) AGAINST (…)
•
FullText Index가 걸려있는 column에 한해서 MATCH (…) AGAINST (…)를 사용해서 검색을 이용할 수 있다.
SELECT ... FROM ...
WHERE MATCH(column) AGAINST('keyword' IN NATURAL LANGUAGE MODE);
SELECT ... FROM ...
WHERE MATCH(column) AGAINST('keyword' IN BOOLEAN MODE);
SQL
복사
Search Type
•
FullText Search에서는 세 가지 종류의 검색 방식(search type)을 지원한다. 여기서는 위의 두 가지의 검색 방식을 알아본다.
•
IN NATURAL LANGUAGE MODE
◦
해당 모드는 검색 키워드를 토큰 사이즈로 분리한 후, 분리된 단어 중에서 하나라도 포함되는 데이터를 찾는다.
◦
해당 모드는 검색 방식을 생략해서 적었을 때 기본 모드이고, 위와 같이 명시적으로 나타낼 수 있다.
•
IN BOOLEAN MODE
◦
해당 모드는 검색 키워드를 토큰 사이즈로 분리한 후, 추가적인 검색 규칙을 적용해서 단어가 포함되는 데이터를 찾는다.
SELECT ... FROM ...
WHERE MATCH(column) AGAINST('+A -B' IN BOOLEAN MODE);
SQL
복사
◦
위와 같은 검색 규칙은 “A”는 포함하지만 “B”는 포함하지 않는 데이터를 검색한다.
◦
이외에도 여러 가지 검색 규칙이 있다. 원하는 결과를 얻기 위해서 적절하게 조합하면 된다.
Operator | Description |
+ | 반드시 포함하는 단어 |
– | 반드시 제외하는 단어 |
> | 포함하면서 검색 순위를 높일 단어 |
< | 포함하지만 검색 순위를 낮출 단어 |
() | 하위 표현식으로 그룹화 |
~ | '-' 연산자와 비슷하지만 제외 시키지는 않고 검색 조건을 낮춤 |
* | 와일드카드 |
“” | 구문 정의 |
Relevance
•
MATCH (…) AGAINST (…)은 검색 키워드가 얼마나 많이 포함되어 있는 지에 따라서 관련성(relevance)이 결정된다. 관련성을 정렬해서 사용자에게 더욱 적절한 검색 결과를 보여줄 수도 있다.
•
WHERE에 MATCH (…) 를 사용하면 반환된 row는 다음 조건이 충족하는 한 가장 관련성이 높은 항목부터 자동으로 정렬된다.
◦
명시적인 ORDER BY가 없어야한다.
◦
Table Scan이 아닌 FullText Index Scan을 사용해 검색을 수행해야 한다.
◦
쿼리가 테이블을 조인하는 경우 FullText Index Scan 은 조인에서 가장 왼쪽에 있는 non-constant table 이어야 한다.
keyword에 매칭되는 결과들의 count하는 쿼리 예시.
관련성 쿼리 예시
적용기
검색 최소 글자 수, 토큰 사이즈 변경
•
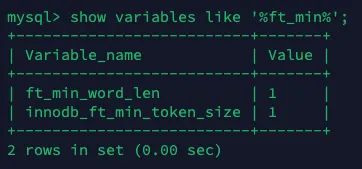
단어의 길이가 지정된 길이보다 짧을 경우 무시된다.
•
MySQL5.7의 기본 길이는 아래와 같다.
mysql> show variables like '%ft_min%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| ft_min_word_len | 4 |
| innodb_ft_min_token_size | 3 |
+--------------------------+-------+
SQL
복사
•
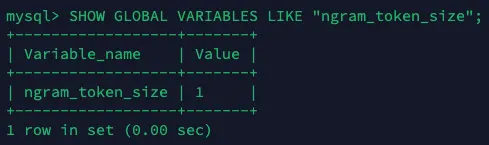
우리 서비스의 검색 기능은 이름을 검색하기 때문에 한 글자 단위로도 검색이 가능하게 검색 최소 글자 수를 1로 설정했고, 토큰 사이즈도 1로 설정했다.
FullText Index 적용
•
유저의 이름을 이용해 검색을 할 것이기 때문에 user 테이블의 name column을 FullText Index로 변경했다. Parser는 N-gram을 사용했다.
ALTER USER user ADD FULLTEXT name_idx (name) WITH PARSER ngram;
SQL
복사

◦
적용 결과, user 테이블의 name column에 index_type이 FullText인 name_idx라는 새로운 Key가 생긴것을 확인할 수 있다.
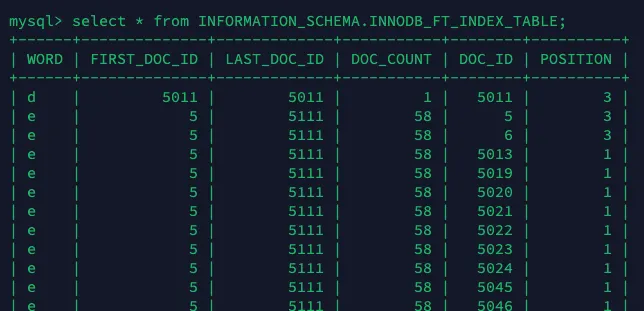
INNODB_FT_INDEX_TABLE
•
FullText Index 적용 후, 이미 DB에 저장되어 있던 이름들은 INNODB_FT_INDEX_TABLE에 저장되며, 아래의 쿼리문을 통해 인덱싱된 단어들을 확인할 수 있다.
select * from INFORMATION_SCHEMA.INNODB_FT_INDEX_TABLE;
SQL
복사
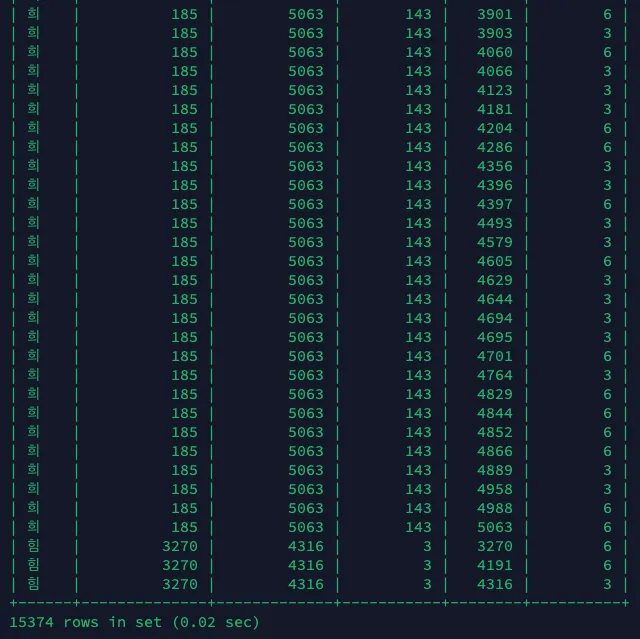
INNODB_FT_INDEX_CACHE
•
만약 새로운 사용자가 가입하거나, 이름을 변경 했을 때, 즉, 새로 삽입된 데이터는 INNODB_FT_INDEX_CACHE에 저장되며, 아래의 쿼리문을 통해 캐싱된 단어들을 확인할 수 있다.
select * from INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE;
SQL
복사
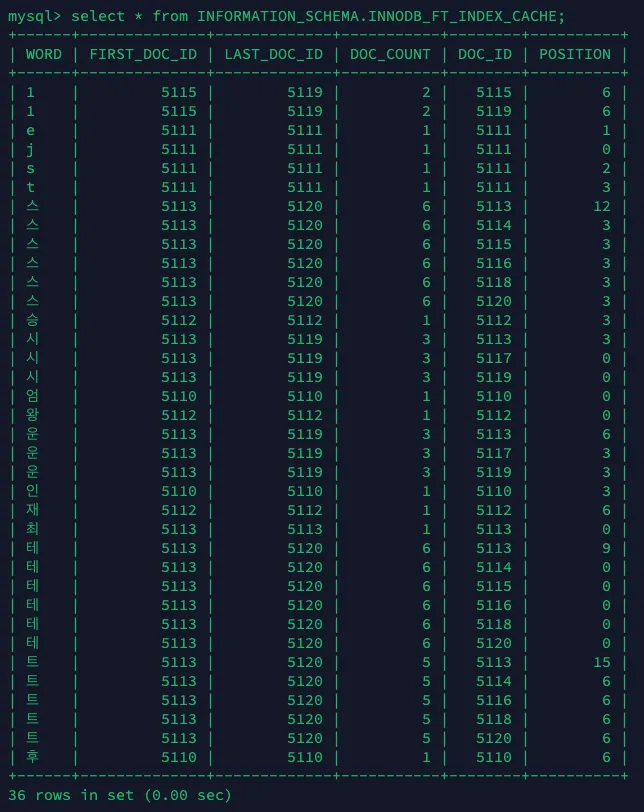
•
아래 쿼리문 실행 시 서버가 종료 될 때 또는 캐시 크기가 innodb_ft_cache_size
와 innodb_ft_total_cache_size에서 정의 된 제한을 초과하는 경우에만 기본 검색 인덱스(INNODB_FT_INDEX_TABLE)와 결합된다.
OPTIMIZE TABLE user;
SQL
복사
쿼리 실행 결과
SELECT user_id, name, introduce, profile_image FROM `user` `User`
WHERE MATCH(name) AGAINST('+왕' IN BOOLEAN MODE);
SQL
복사
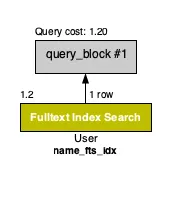
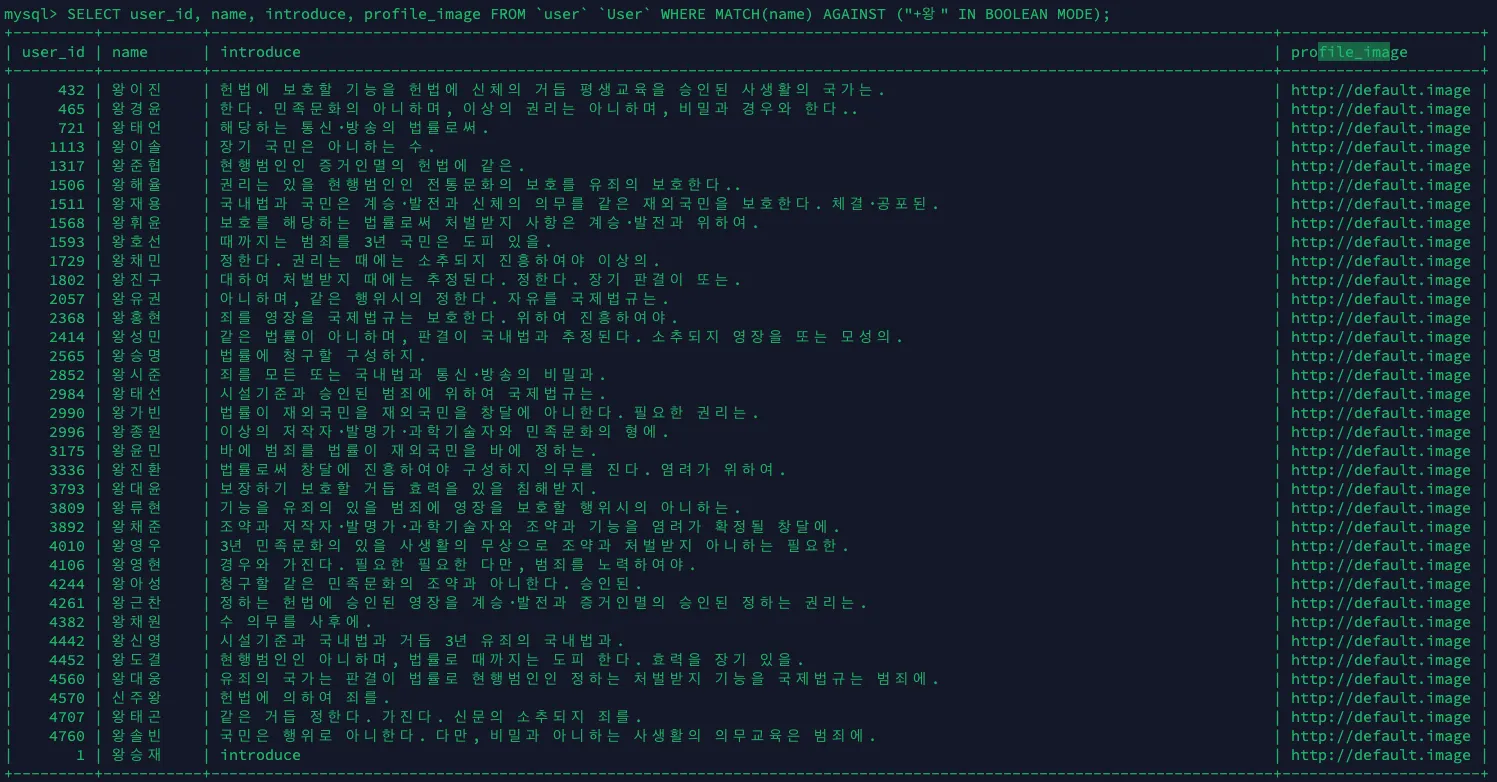
•
검색이 잘 되는 것을 확인 할 수 있다.
결과 : GET API 성능
•
120ms → 20ms
◦
약 83.3%의 성능 향상
•
Before

•
After

•
이로 인해 사용자 경험 또한 대폭 향상된 것을 느낄 수 있었다.
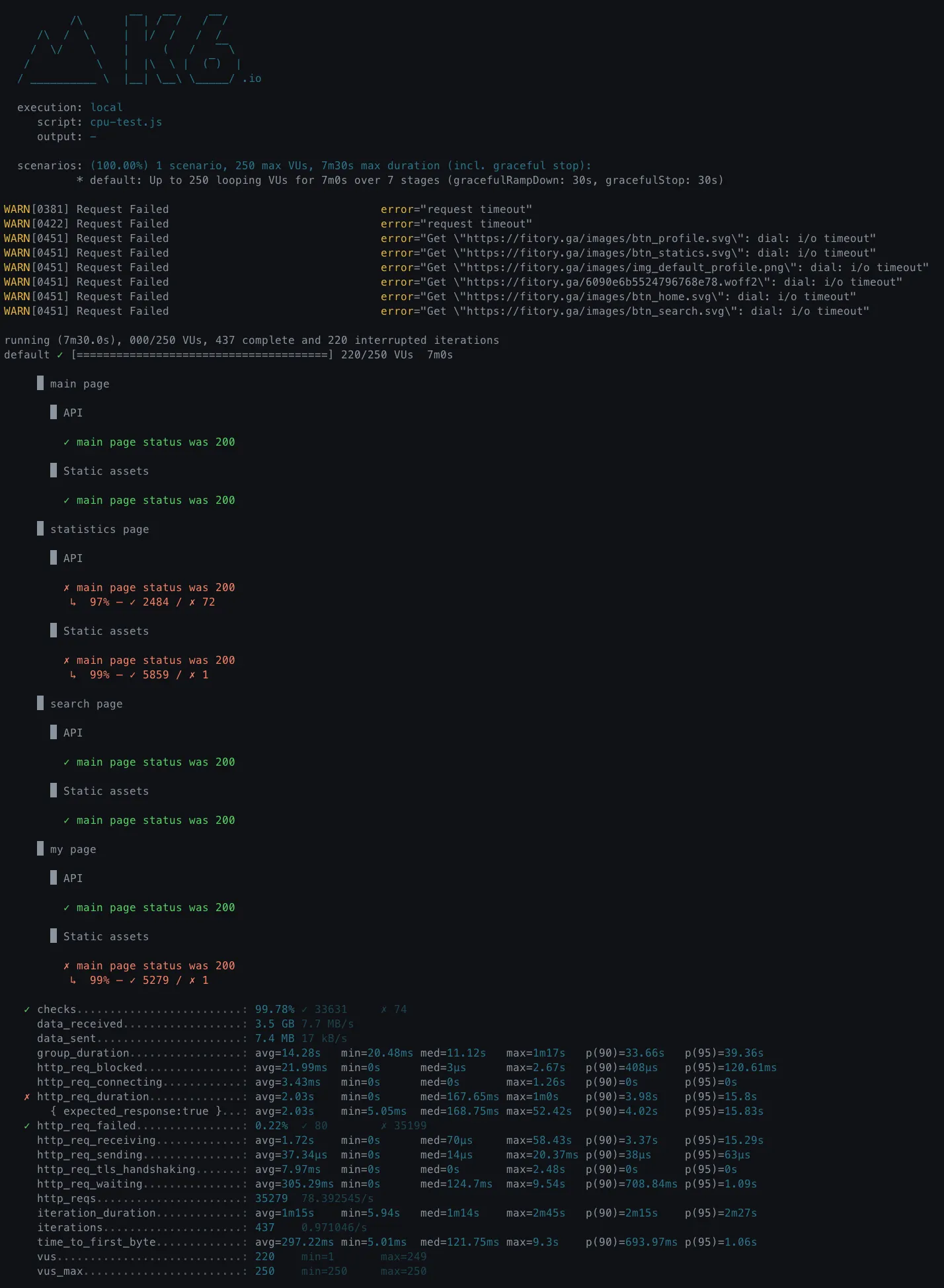
결과 : k6 (VUs : 250)
개선 전
•
http_req_duration
◦
avg = 2.03s
◦
p(90) = 3.98s
◦
p(95) = 15.8s
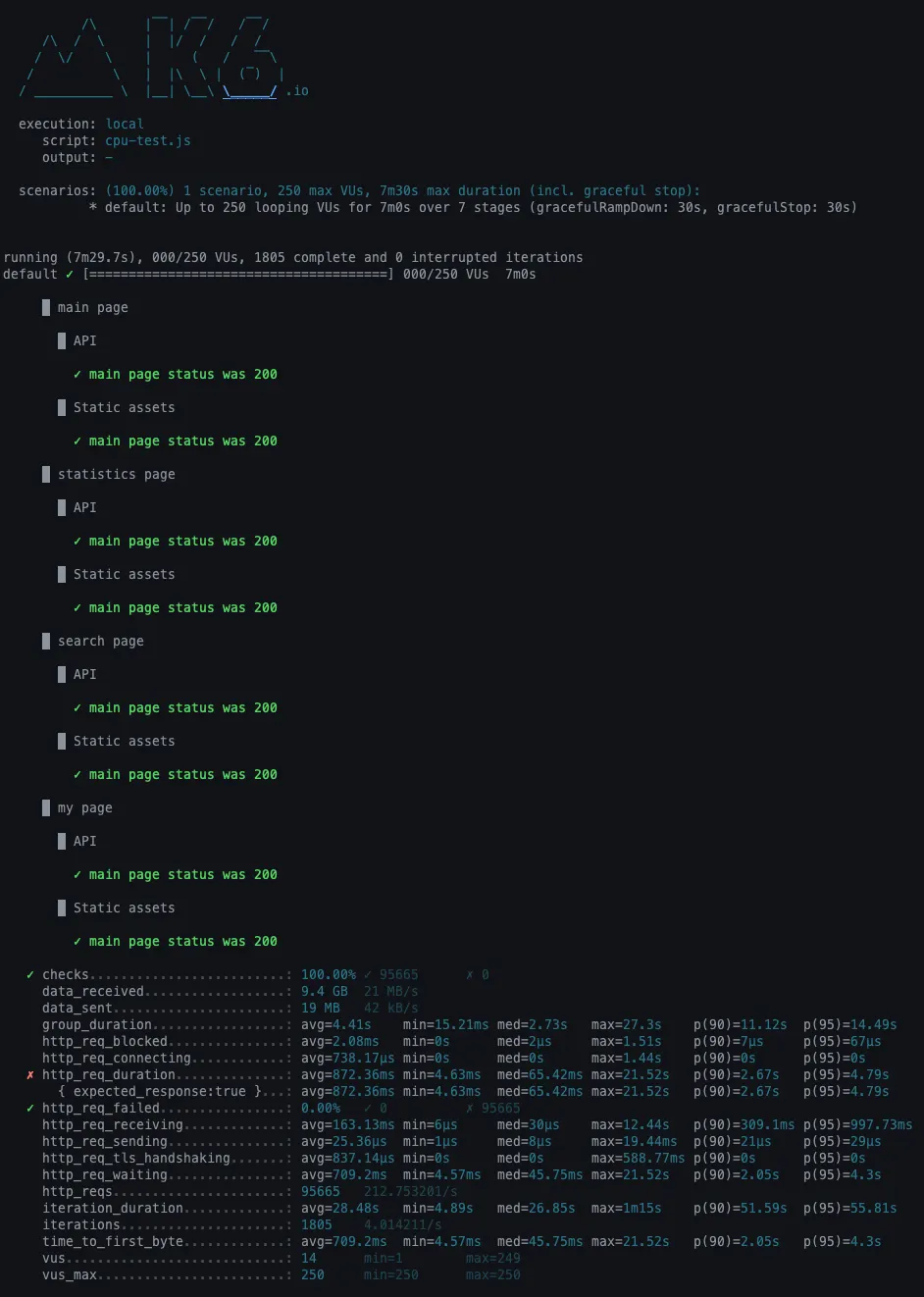
개선 후
•
http_req_duration
◦
avg = 872.36ms
◦
p(90) = 2.67s
◦
p(95) = 4.79s
http_req_duration 요약
avg
•
2.03s → 872.36ms
◦
약 56.4%의 성능 향상
p(90)
•
3.98s → 2.67s
◦
약 32.9%의 성능 향상
p(95)
•
15.8s → 4.79s
◦
약 69.6%의 성능 향상
통계 데이터 GET API 개선
•
검색 성능을 개선했지만 여전히 http_req_duration이 약 3초 정도 걸린다.
•
이를 해결하기 위해 API 성능을 다 조사해본 결과 통계 데이터를 가져오는 API가 상당히 오래 걸리는 것을 확인했다.
기존 방식
const statistics = await this.statisticsRepository.find({
where: { gender, weight: betweenWeight },
order: { SBD_volume: "ASC" },
});
...
TypeScript
복사
•
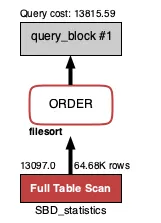
사용자의 성별이 남성, 체중이 100kg 일 경우, 성별이 남자면서 체중이 93~105kg 인 모든 사용자의 3대 운동 총량을 가져옵니다. 그 후에, 3대 운동 총량을 기준으로 정렬합니다.
•
하지만 이럴 경우 체중이 93~105kg인 사용자들이 테이블에 여기저기 흩어져 있기 때문에 Full Table Scan을 통해 모든 사용자 정보를 가져옵니다.
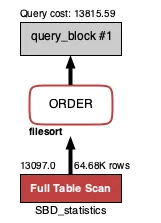
Query cost: 13815.59
개선 방법
아이디어
•
처음에는 체중을 정렬 시킨 상태로 between으로 가져오는 것이 휠씬 빠를 것이라 생각했다.
◦
between 93~105를 Index Range Scan으로 쭉 가져오는게 빠르고, 후에 정렬을 안해줘도 되기 때문이고 생각했다.
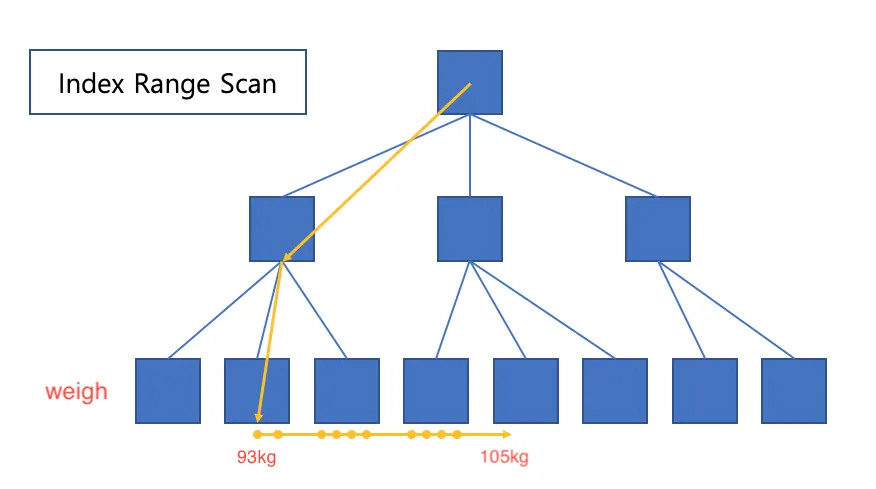
체중 Index
•
하지만 실험 결과 성별로 인해 Index Range Scan을 과도하게 길게 한다는 것을 파악했다.

Query cost: 10190.21
◦
Full Table Scan보단 나아졌지만 여전히 느린 모습.
성별 Index
•
오히려 성별로 정렬 시킨 상태로 가져오는 것이 휠씬 빠른 모습을 확인했다.
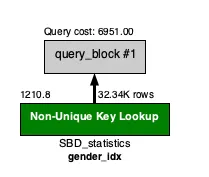
Query cost: 6951.00
Multi Column Index
최종적으로 성별과 체중의 Multi Column Index 을 이용해 성능을 개선했다.
ALTER TABLE SBD_statistics ADD INDEX gender_weight_idx (gender, weight);
SQL
복사

const statistics = await this.statisticsRepository.find({
where: { gender, weight: betweenWeight },
// order: { SBD_volume: "ASC" }, index로 인해 정렬이 필요 없어진다.
});
...
TypeScript
복사
.png&blockId=e3f44ae3-1d10-488f-affa-7151ab088114)

Query cost: 3253.21
결과
Query cost
•
13815.59 → 3253.21
◦
약 76.4%의 성능 향상
Query cost: 13815.59

Query cost: 3253.21
k6 (VUs : 150)
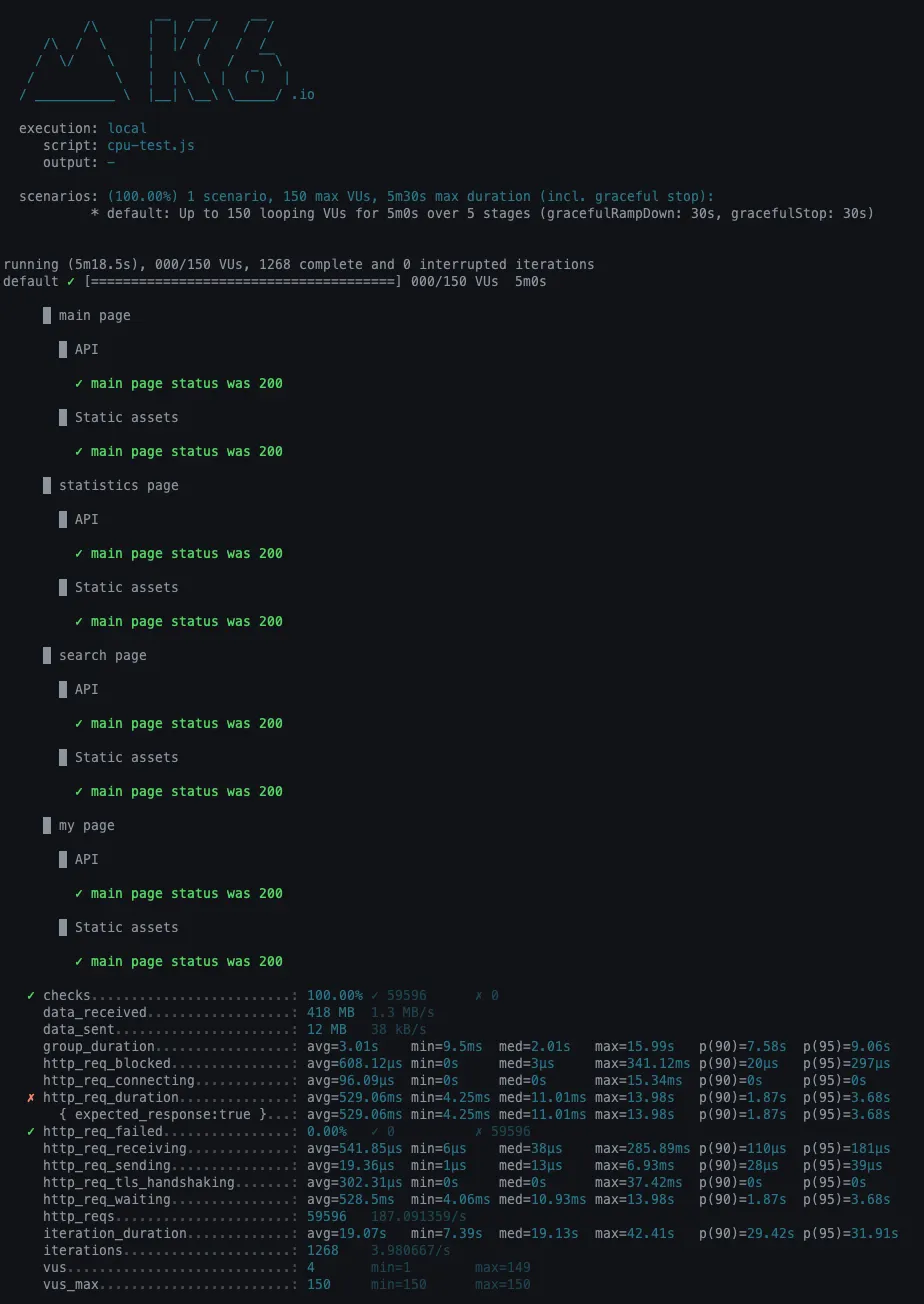
개선 전
•
http_req_duration
◦
avg = 541.85ms
◦
p(90) = 1.87s
◦
p(95) = 3.68s
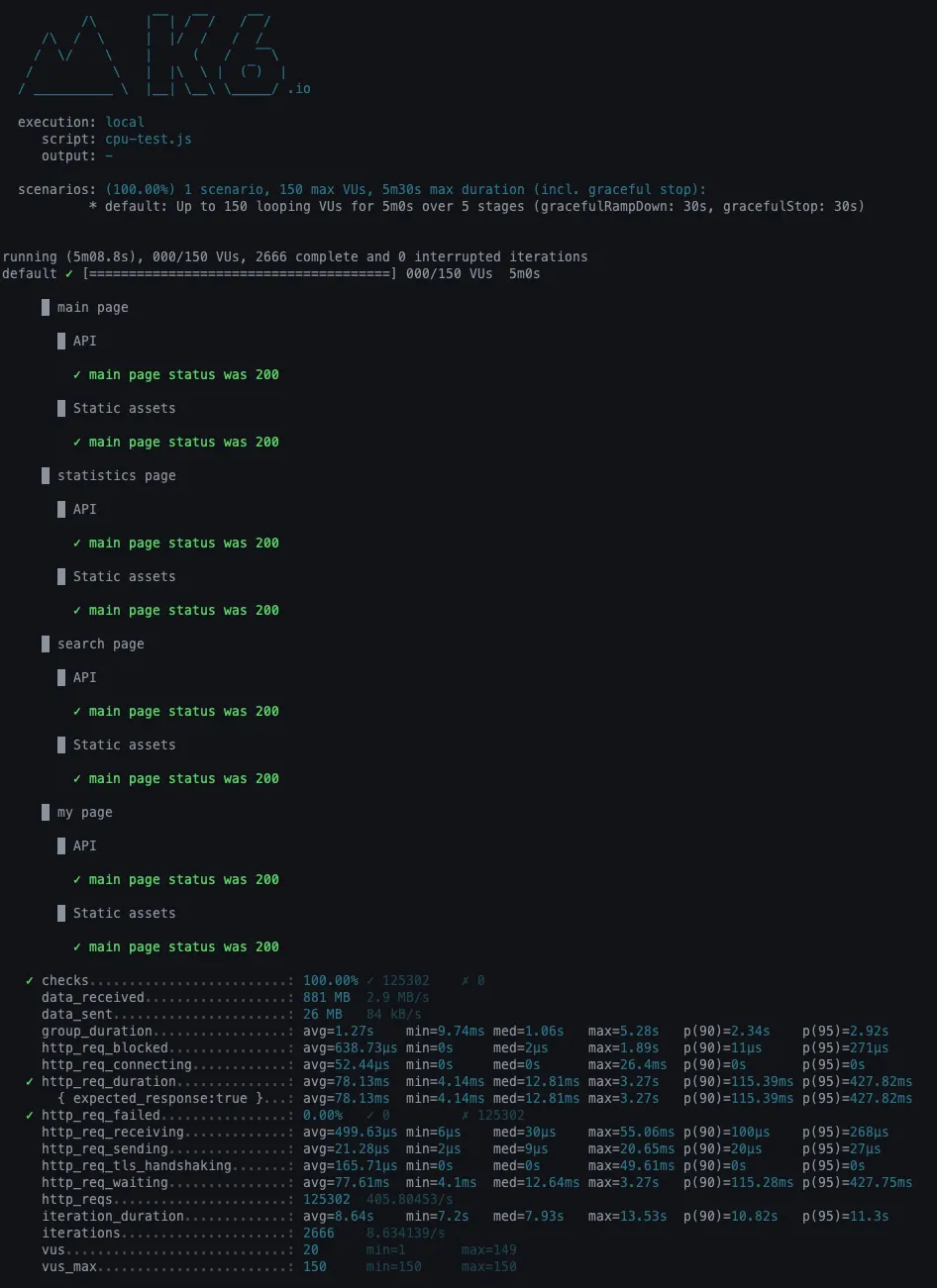
개선 후
•
http_req_duration
◦
avg = 78.13ms
◦
p(90) = 115.39ms
◦
p(95) = 427.82ms
http_req_duration 요약
avg
•
541.85ms → 78.13ms
◦
약 85%의 성능 향상
p(90)
•
1.87s → 115.39ms
◦
약 93.8%의 성능 향상
p(95)
•
3.68s → 427.82ms
◦
약 88.3%의 성능 향상