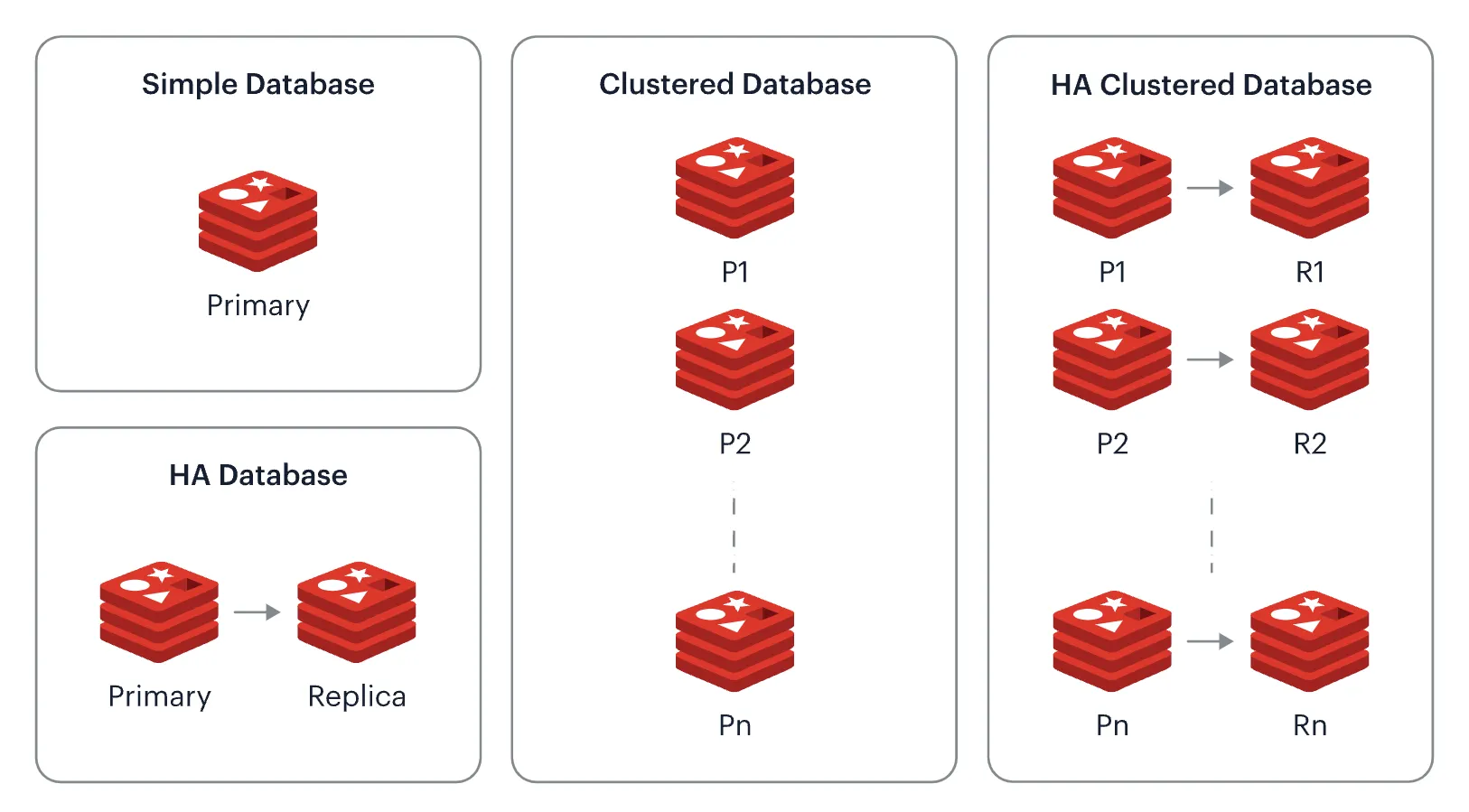
대량 데이터 처리, 저장 방법
Data Partitioning
•
큰 Table이나 인덱스를 관리하기 쉬운 단위로 분리하는 방법을 의미한다.
•
대량의 데이터를 처리하기 위해 DBMS 안에서 분할하는 방식이다.
•
한 대의 DBMS만 설치하면 된다.
•
Scale Up → 1 Machine → 1 DBMS → Data Partitioning
장점
•
가용성 (Availability)
◦
물리적인 Partitioning으로 인해 전체 데이터의 훼손 가능성이 줄어들고 데이터 가용성이 향상된다.
•
관리용이성 (Manageability)
◦
큰 Table들을 제거하여 관리를 쉽게 해준다.
•
성능 (Performance)
◦
특정 DML과 Query의 성능을 향상시킴, 주로 대용량 Data Write 환경에서 효율적이다.
◦
많은 Insert가 있는 OLTP 시스템에서 Insert 작업들을 분리된 파티션들로 분산시켜 경합을 줄인다.
단점
•
Table간의 Join에 대한 비용이 증가한다.
•
테이블과 인덱스를 별도로 파티션 할수는 없다. 테이블과 인덱스를 같이 Partitioning 하여야 한다.
분할 범위
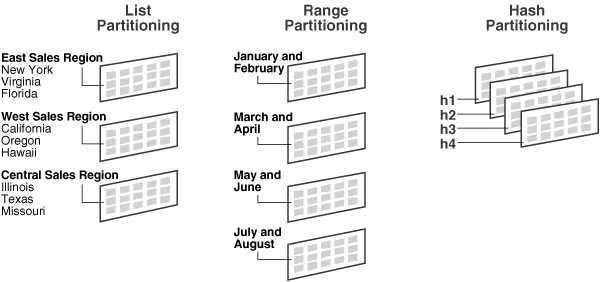
•
Range partitioning
◦
연속적인 숫자나 날짜 기준으로 partitioning 한다.
◦
손쉬운 관리 기법 제공 에 따른 관리 시간의 단축할 수 있다.
◦
ex) 우편번호, 일별, 월별, 분기별 등 의 데이터에 적합하다.
•
List partitioning
◦
특정 Partition에 저장 될 Data에 대한 명시적 제어 가능하다.
◦
분포도가 비슷 하며, 많은 SQL에서 해당 Column의 조건이 많이 들어오는 경우 유용하다.
◦
Multi-Column Partition Key를 제공하기 힘들다.
◦
ex) [한국, 일본, 중국 → 아시아] [노르웨이, 스웨덴, 핀란드 → 북유럽]
•
Composite partitioning
◦
Composite Partition은 Partition의 Sub-Partitioning 을 말한다.
◦
큰 파티션에 대한 I/O 요청을 여러 partition으로 분산할 수 있다.
◦
Range Partitioning을 할 수 있는 Column이 있지만, Partitioning 결과 생성된 Partition이 너무 커서 효과적으로 관리할 수 없을 때 유용하다.
◦
Range-list, Range-Hash
•
Hash partitioning
◦
Partition Key의 Hash값에 의한 Partitioning.
▪
균등한 데이터 분할 가능
◦
Select 시 조건과 무관하게 병렬 Degree 제공.
▪
질의(query) 성능 향상
◦
특정 Data가 어느 Hash Partition에 있는지 판단 불가.
◦
Hash Partition은 파티션을 위한 범위가 없는 데이터에 적합하다.
분할 방법
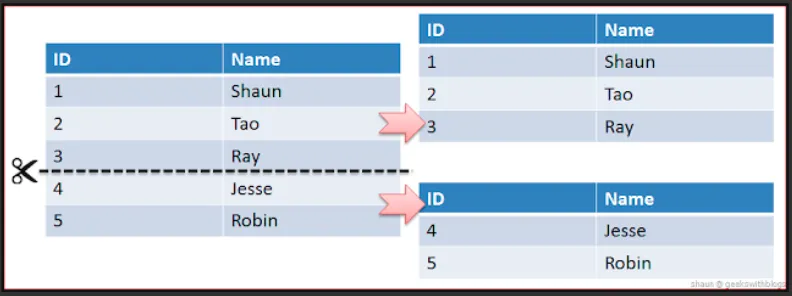
•
Horizontal Partitioning
◦
장점
▪
데이터의 개수를 기준으로 나누어 Partitioning한다.
▪
데이터의 개수가 작아지고 따라서 index의 개수도 작아지게 된다.
▪
자연스럽게 성능은 향상된다.
◦
단점
▪
서버간의 연결과정이 많아진다.
▪
데이터를 찾는 과정이 기존보다 복잡하기 때문에 latency가 증가하게 된다.
▪
하나의 서버가 고장나게 되면 데이터의 무결성이 깨질 수 있다.
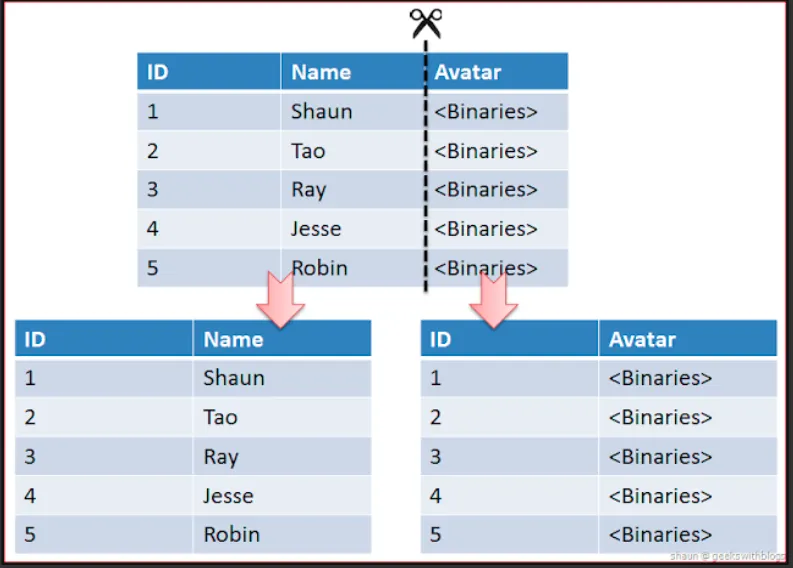
•
Vertical Partitioning
◦
테이블의 컬럼을 기준으로 나누어 Partitioning한다.
◦
정규화하는 과정도 이와 비슷하다고 볼 수 있지만 Vertical Partitioning은 이미 정규화된 Data를 분리하는 과정이다.
◦
자주 사용하는 컬럼등을 분리시켜 성능을 향상시킬 수 있다.
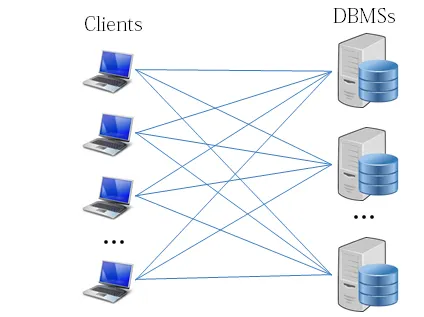
Data Sharding
•
대량의 데이터를 처리하기 위해 여러 개의 DBMS에 분할하는 기술이다.
•
같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법을 의미한다.
•
DBMS안에서 데이터를 나누는 것이 아니고 DBMS 밖에서 데이터를 나누는 방식이다.
◦
그러므로 샤드 수에 따라 여러 대의 DBMS를 설치해야 한다.
•
Scale out → n Machines/VMs → n DBMSs → Data Sharding
Sharding에 필요한 원리
•
분산된 Database에서 Data를 어떻게 Read할 것인가?
•
분산된 Database에 Data를 어떻게 잘 분산시켜서 저장할 것인가?
◦
분산이 잘 되지 않고, 한 쪽으로 Data가 몰리게 되면 자연스럽게 Hotspot이 되어 성능이 느려지게 된다.
◦
그렇기 때문에 균일하게 분산하는 것이 중요한 목표이다.
Sharding을 적용하기에 앞서
•
Sharding을 적용한다는것은?
◦
프로그래밍, 운영적인 복잡도는 더 높아지는 단점이 있다.
•
가능하면 Sharding을 피하거나 지연시킬 수 있는 방법을 찾는 것이 우선되어야 한다.
◦
Scale-in
▪
Hardware Spec이 더 좋은 컴퓨터를 사용.
◦
Read 부하가 크다면?
▪
Cache나 Database의 Replication을 적용하는 것도 하나의 방법이다.
◦
Sharding Algorithm
Modular sharding과 Range sharding의 공통된 요구사항은 아래와 같다.
•
라우팅을 위해 구분할 수 있는 유일한 키값이 있어야 한다.
◦
편의상 아래부터는 PK 또는 샤딩키라고 부른다.
•
올바른 DB를 찾을 수 있도록 라우팅이 돼야 한다.
•
설정으로 쉽게 증설이 가능해야 한다.
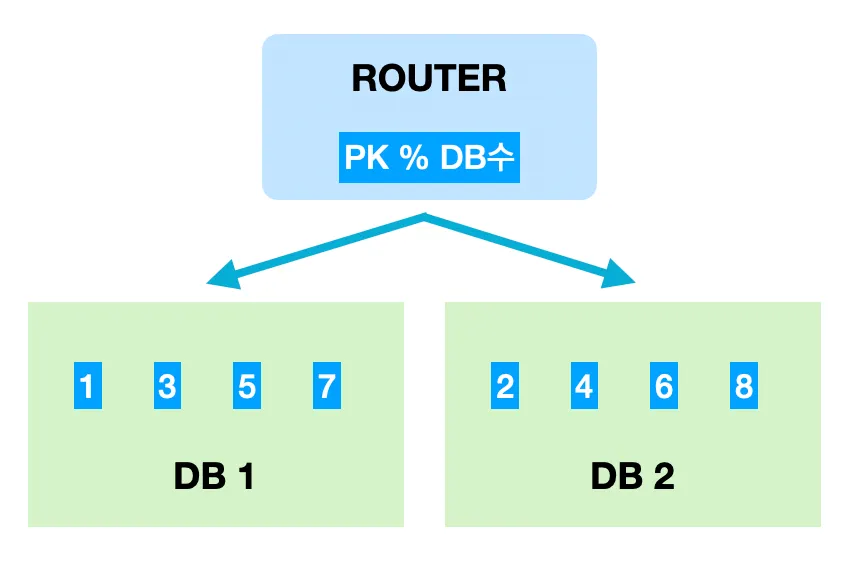
Modular sharding
•
Modular sharding은 PK를 모듈러 연산한 결과로 DB를 특정하는 방식이다.
•
장점
◦
Range sharding에 비해 데이터가 균일하게 분산된다.
•
단점
◦
DB를 추가 증설하는 과정에서 이미 적재된 데이터의 재정렬이 필요하다.
•
Modular sharding은 데이터량이 일정 수준에서 유지될 것으로 예상되는 데이터 성격을 가진 곳에 적용할 때 어울리는 방식이다.
◦
콘텐츠의 유지기간이 제한돼 있고, 데이터가 항상 쌓이기만 하는 상황일 경우 modular sharding을 적용하기에 알맞다.
◦
물론 데이터가 꾸준히 늘어날 수 있는 경우라도 적재속도가 그리 빠르지 않다면 modular sharding을 통해 분산처리하는 것도 고려해볼 법 하다.
•
무엇보다 데이터가 균일하게 분산된다는 점은 트래픽을 안정적으로 소화하면서도 DB리소스를 최대한 활용할 수 있는 방법이기 때문이다.
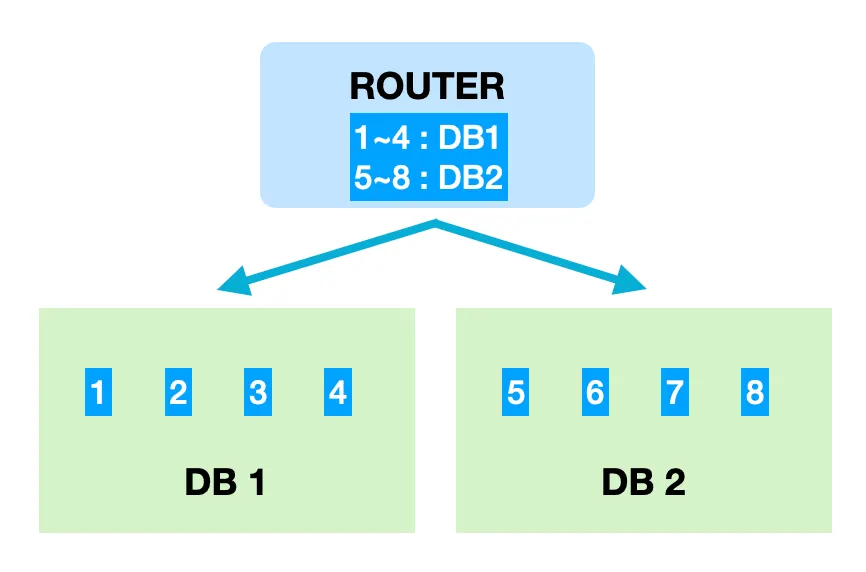
Range sharding
•
Range sharding은 PK의 범위를 기준으로 DB를 특정하는 방식이다.
•
장점
◦
Modular sharding에 비해 기본적으로 증설에 재정렬 비용이 들지 않는다.
•
단점
◦
일부 DB에 데이터가 몰릴 수 있다.
•
Range sharding의 가장 큰 장점은 증설작업에 드는 비용이 크지 않다는 점이다.
•
데이터가 급격히 증가할 여지가 있다면 레인지방식도 좋은 선택일 것이다.
•
다만 단점으로 주로 활성유저가 몰린 DB로 트래픽이나 데이터량이 몰릴 수 있다.
◦
기껏 분산처리를 했는데 이런 상황이 발생하면 또 다시 부하 분산을 위해 해당 DB를 분할하여 재정렬하는 작업이 필요하다.
◦
반대로 트래픽이 저조한 DB는 통합작업을 통해 유지비용을 아끼도록 관리해야 한다.

Router
•
모듈러와 레인지방식이 어떤 기준으로 데이터를 분산시킬지에 대한 명세를 정의한 것이라면, 실제로 분산된 DB에 접근하기 위한 논리적인 작업은 라우터가 담당하게 된다.
Topology
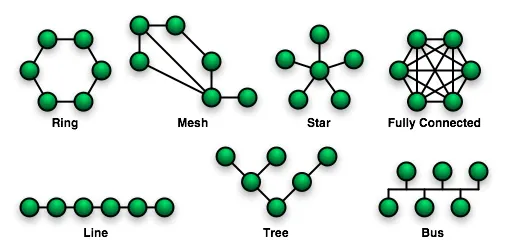
단일 장애점(Single point of failure, SPOF)이 있는 Topology
스타(Star), 트리(Tree) → Greenplum, HBase
Redis Sentinel이 얼핏 SPOF처럼 보이지만 엄밀히 SPOF는 아니다

Greenplum Database Architecture

•
Active master는 1개만 필요하고, 백업용 Standby master를 두고 Active master 다운 시 Standby master가 master의 역할을 이어 받는다.
•
마스터는 데이터가 어느 세그먼트 노드에 있는지와 세션(connection) 정보를 관리한다.
•
클라이언트는 항상 마스터를 통해서만 쿼리를 수행할 수 있다.
HBase Architecture
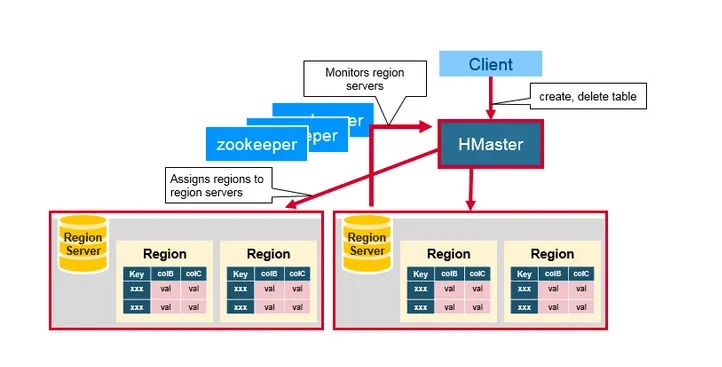
•
Hbase는 HDFS(Hadoop Distributed File System)에 기반한다.
•
master는 Region 정보를 가지고 있고, HDFS의 name node에 위치한다.
•
클라이언트는 master로부터 Region 정보를 가져와서, 연결은 master를 거치지 않고 Region 서버에 직접한다.
◦
따라서 master는 세션 정보를 가지고 있지 않는다.
◦
그러므로 Region 정보가 복제된 여러 개의 master를 둘 수 있다.
•
HBase는 단일 장애점(SPOF)을 가지는 구조는 아니지만, 소수의 master가 다운될 경우 HBase를 사용할 수 없는 구조이다.
•
굳이 말하자면 Multiple Points of Failure(MPOF) 아키텍처이다.
단일 장애점(Single point of failure)이 없는 Topology
완전 메쉬형(Fully connected mesh topology) → Redis Cluster
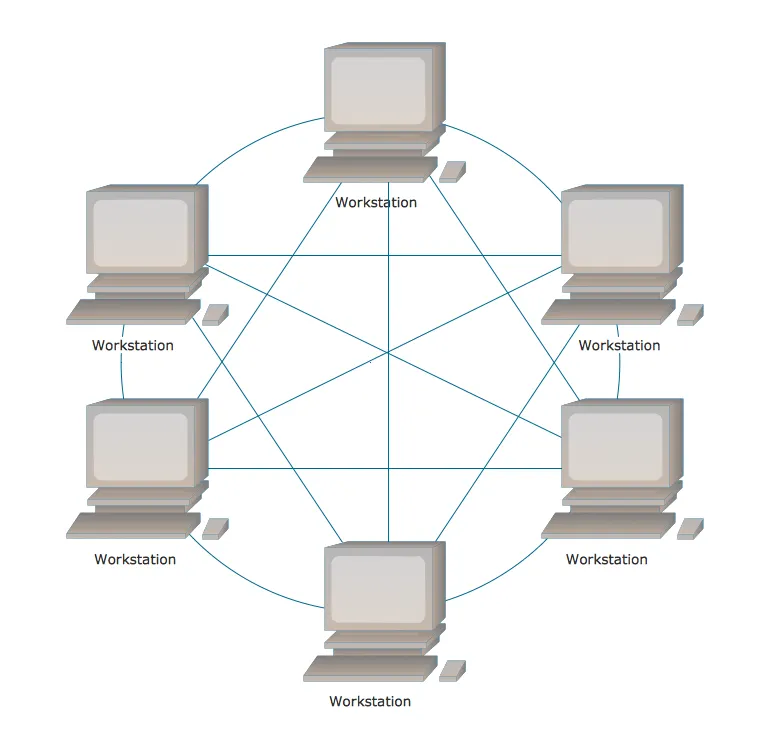
Redis Cluster Architecture
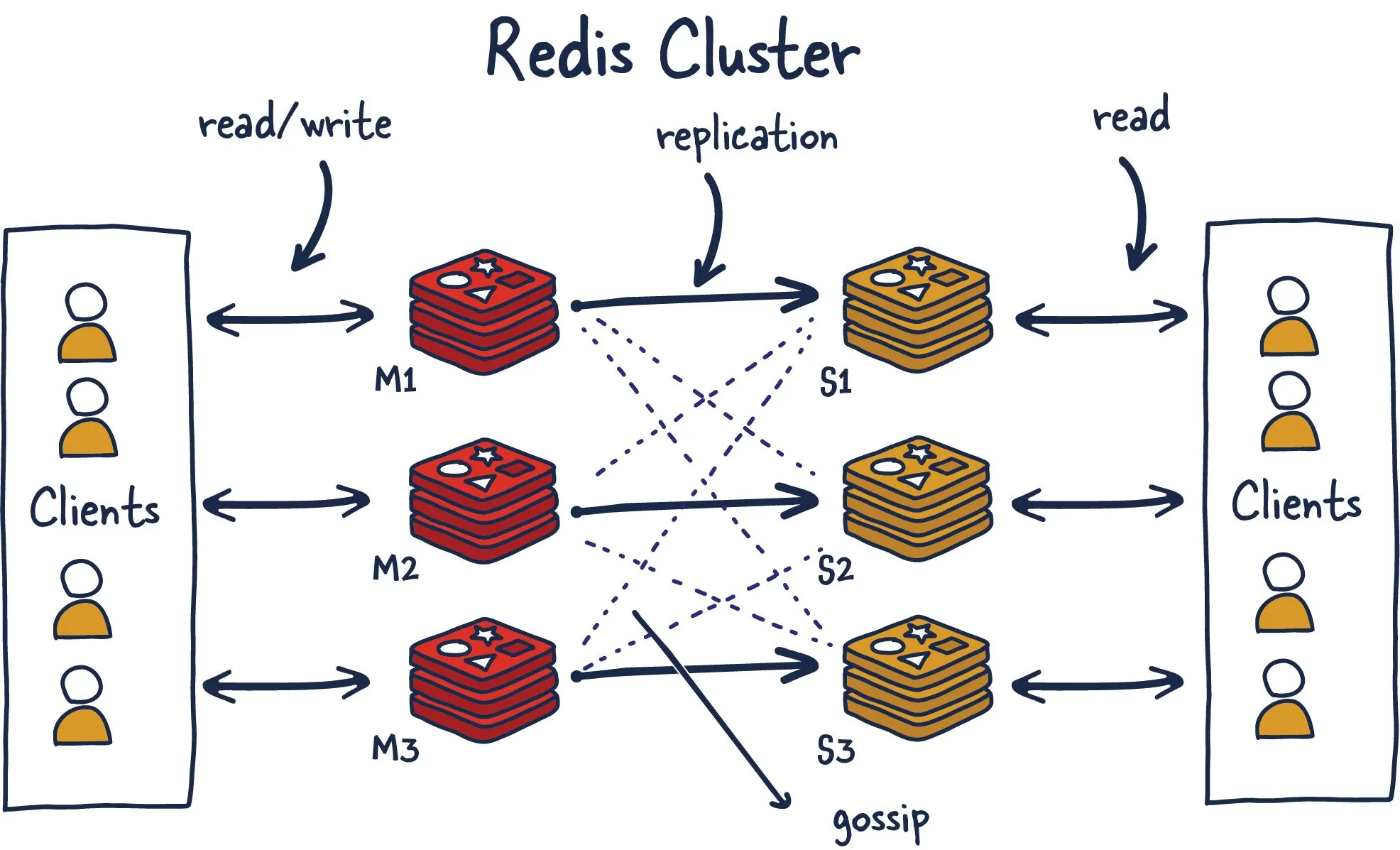
•
Clone 노드를 포함한 모든 노드가 서로를 확인하고 정보를 주고 받는다.
◦
→ Fully Connected Mesh Topology.
•
Greenplum이나 HBase 같이 별도의 master 노드를 두지 않는 구조이다.
•
모든 노드가 클러스터 구성 정보(슬롯 할당 정보)를 가지고 있다.
•
클라이언트는 어느 노드든지 접속해서 클러스터 구성 정보(슬롯 할당 정보)를 가져와서 보유하며, 입력되는 키(key)에 따라 해당 노드에 접속해서 처리한다.
•
일부 노드가 다운되어도 다른 노드에 영향을 주지 않는다.
•
단, 과반수 이상의 노드가 다운되면 Redis Cluster는 멈춘다.
•
데이터를 처리하는 master 노드는 1개 이상의 복제 노드를 가질 수 있다.