
Index에 대해
[Table #1] - Index(id, age)
where id = 3;
CREATE TABLE crystalcube
(
id INT(11) UNSIGNED PRIMARY KEY NOT NULL AUTO_INCREMENT,
age INT(11) NOT NULL DEFAULT 0,
name VARCHAR(32) NOT NULL,
comment VARCHAR(64),
extra VARCHAR(16),
INDEX(id, age)
);
SQL
복사
insert into crystalcube values(default, 10, 'john', 'my friend', '13');
insert into crystalcube values(default, 30, 'Emily', 'my girl friend', '12');
insert into crystalcube values(default, 15, 'Alexis', 'my daughter, my family', '13');
insert into crystalcube values(default, 15, 'Michael', 'my son, my family', '12');
insert into crystalcube values(default, 27, 'Ashley', 'my wife, my family', '1');
SQL
복사
EXPLAIN SELECT * FROM crystalcube WHERE id = 3;
SQL
복사
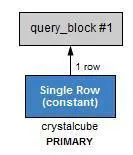
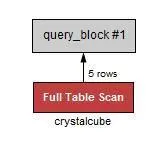
where age = 10;
EXPLAIN SELECT * FROM crystalcube WHERE age = 10;
SQL
복사
•
테이블을 생성할때, INDEX(id, age) 라고 했는데 이것은 id 를 첫번째 index로, 그리고 두번째 index 로 age 컬럼을 쓰겠다는 것이다.
•
의도한것처럼 id 도 index 로 하고, age 도 index 로 하려면 따로따로 선언해 주어야 한다.
[Table #2] - Index(id), Index(age)
CREATE TABLE crystalcube
(
id INT(11) UNSIGNED PRIMARY KEY NOT NULL AUTO_INCREMENT,
age INT(11) NOT NULL DEFAULT 0,
name VARCHAR(32) NOT NULL,
comment VARCHAR(64),
extra VARCHAR(16),
INDEX(id),
INDEX(age)
);
SQL
복사
WHERE age = 15 AND extra = ‘13’;
SELECT * FROM crystalcube WHERE age = 15 AND extra = '13'
SQL
복사
•
Table #2 인 경우에는 index 를 타지 않고, Full Table Scan 이 된다. 위 경우를 처리하려면, INDEX(age, extra) 를 추가시켜 주어야 한다.
[Table #3] - Index(extra)
CREATE TABLE crystalcube
(
id INT(11) UNSIGNED PRIMARY KEY NOT NULL AUTO_INCREMENT,
age INT(11) NOT NULL DEFAULT 0,
name VARCHAR(32) NOT NULL,
comment VARCHAR(64),
extra VARCHAR(16),
INDEX(extra)
);
SQL
복사
•
위 테이블에서 extra 컬럼은 VARCHAR 이라는 점에 주목해야 한다.
WHERE extra = 1;
SELECT * FROM crystalcube WHERE extra = 1;
SQL
복사
•
extra가 문자열인데도 불구하고, quote(')로 묶지 않았다.
•
에러가 날까? 아니다. MySQL 에서 내부적으로 변환해서 제대로 검색해 준다.
WHERE extra = 1; vs WHERE extra = ‘1’;
•
아래 두 쿼리의 효율은 어떻게 될까?
•
하나는 위와 마찬가지로 quote 로 감싸지 않은 경우고, 하나는 감싼 경우이다. 나머진 동일하다.
EXPLAIN SELECT * FROM crystalcube WHERE extra = 1;
SQL
복사
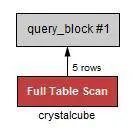
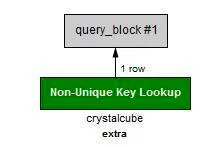
EXPLAIN SELECT * FROM crystalcube WHERE extra = '1';
SQL
복사
•
결과는 완전 다르다.
•
처음처럼 quote 로 감싸지 않은 경우, Full Table Scan 을 하게 된다.
•
하지만 아래처럼 quote로 감싸주면 index 를 타게 된다.
[Table #4] - Index(age), Index(extra)
CREATE TABLE crystalcube
(
id INT(11) UNSIGNED PRIMARY KEY NOT NULL AUTO_INCREMENT,
age INT(11) NOT NULL DEFAULT 0,
name VARCHAR(32) NOT NULL,
comment VARCHAR(64),
extra VARCHAR(16),
INDEX(age),
INDEX(extra)
);
SQL
복사
WHERE age = 15 AND extra = 12;
EXPLAIN SELECT * FROM crystalcube WHERE age = 15 AND extra = 12;
SQL
복사
•
한 번만에 검색이 될까? 아니다.
•
앞서 말한대로 varchar 의 경우 quote(’) 로 묶어주지 않으면 index를 사용하지 않는다.
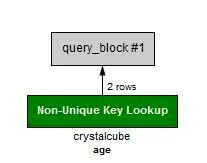
age만 사용된 것을 볼 수 있다
WHERE age = 15 AND extra = ‘12’;
EXPLAIN SELECT * FROM crystalcube WHERE age = 15 AND extra = '12';
SQL
복사
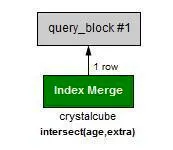
age와 extra 가 사용되었다
•
하지만 이렇게 index 두 개가 모두 사용되는 경우는 보장할수 없는것 같다.
•
위 경우에서, 레코드를 늘려보면, 아래처럼 explain 결과가 변경됩니다.
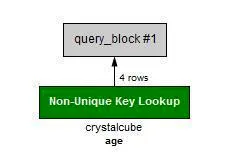
age만 사용된 것을 볼 수 있다
•
age 하나만 index 로 사용되고 있다.
•
아마 경우에 따라 내부 알고리즘에 의해 효율적인 column을 index로 사용하는듯 하다.
◦
•
사실 위 경우라면 age가 아니라 extra를 index로 사용 가능하다.
•
하지만 extra를 index 로 쓰면 아래처럼 4개의 row 가 아니라, 8개의 row가 access 된다.
◦
age - 4개의 row access.
◦
extra - 8개의 row access
◦
그렇기에 내부 알고리즘이 자동으로 age index를 사용.
EXPLAIN SELECT * FROM crystalcube FORCE INDEX(extra) WHERE age = 15 and extra = '12';
SQL
복사
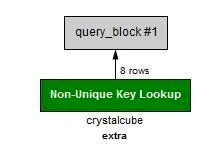
WHERE age = 15 OR extra = '13';
EXPLAIN SELECT * FROM crystalcube WHERE age = 15 OR extra = '13';
SQL
복사
•
AND가 아닌 OR 인 경우.
•
Full Table Scan을 하게 된다. index 를 타지 않는다.
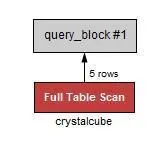
•
age 와 extra 모두 index를 설정했지만 사용하지 않는다.
•
이유는 간단하다. age로만 검색한 경우 age로 index화된 곳에서 검색하면 된다. extra로만 검색할 경우에는 extra로 index화된 곳에서 검색하면 된다.
•
하지만 age와 extra 둘다 동시에 index화 시킬수 없다. 그래서 Full Table Scan 을 하게 된다.
•
그렇다면 어떻게 이 문제를 해결해야 할까? 지금까지 찾아본 바로는 Union을 사용하는게 그나마 효율적인 것 같고, 정석인듯 하다.
EXPLAIN
SELECT * FROM crystalcube WHERE age = 15
UNION
SELECT * FROM crystalcube WHERE extra = '13';
SQL
복사
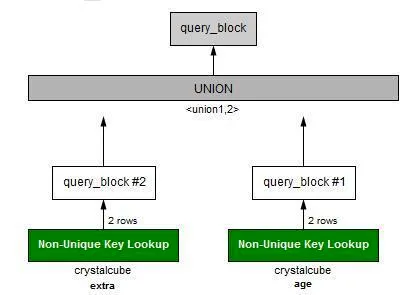
•
최종 결과에 대한 레코드는 3개인데, 4개의 row를 탐색했다.
•
UNION이 기본적으로 DISTINCT 시켜준다는 것을 생각해보면 쉽게 이해가 간다. UNION ALL 이 아니라는 거다.
•
결과는 4개고 중복된게 1개 있어서, 레코드는 실제로 3개가 return된다.
Pagination
[Table #5] - Index(age), Index(extra)
CREATE TABLE crystalcube
(
id INT(11) UNSIGNED PRIMARY KEY NOT NULL AUTO_INCREMENT,
age INT(11) NOT NULL DEFAULT 0,
name VARCHAR(32) NOT NULL,
comment VARCHAR(64),
extra VARCHAR(16),
INDEX(age),
INDEX(extra)
);
SQL
복사
•
각 페이지마다 레코드가 3개씩 보여진다고 가정한다.
•
레코드 갯수가 총 10개이며, 총 4개의 페이지가 있다고 가정한다. (3, 3, 3, 1)
LIMIT 3, 3;
•
두 번째 페이지를 가져온다고 해보자.
•
두 번째 페이지라는건, 앞에 페이지의 레코드가 3개(즉, offset 이 3)이고, 그 뒤로 3개를 가져오라는 이야기이다.
•
그러므로 쿼리는 아래와 같이 된다. 만약 세 번째 페이지라면, LIMIT 6, 3 이 될 것이다.
EXPLAIN SELECT * FROM crystalcube LIMIT 3, 3;
SQL
복사
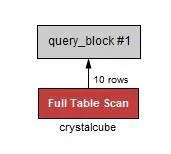
•
기준이 없기 때문에 Full Table Scan이 된다.
•
SELECT * 을 했을 때 나오는 값은 모든 데이터를 가져온 경우고, limit을 사용할 때는 기준을 주어야한다.
•
어떤 기준으로 정렬을 했을 때, offset이 몇 이며, limit이 몇 인지를 알아야 한다.
ORDER BY id LIMIT 3, 3;
•
그렇다면 primary key 를 가지고 order 를 해 보자.
EXPLAIN SELECT * FROM crystalcube ORDER BY id LIMIT 3, 3;
SQL
복사
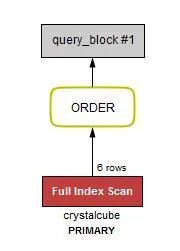
•
처음(10 rows)보다는 좋아졌지만, 6개의 rows를 탐색한다. 이 6개라는것은 offset + limit 의 갯수이다.
◦
LIMIT 2, 3 인 경우에는 5 rows를 탐색한다.
•
이에 따르면 첫 페이지는 엄청 빠르게 탐색이 된다.
•
하지만 페이지가 뒤로 가면 갈수록, 점점 느려진다.
◦
1000 페이지에서 100 개를 가져온다면, 탐색은 1100 개가 될 것이다. 첫페이지는 100 일텐데 말이다.
해결방법으로 많은 곳에서 아래 방식을 사용하라고 권장한다.
WHERE id > 3 ORDER BY id LIMIT 3;
EXPLAIN SELECT * FROM crystalcube WHERE id >3 ORDER BY id LIMIT 3;
SQL
복사
•
id 는 index이거나 primary 이어야 한다. 2 페이지는 id 가 4부터 시작할테니, 위와 같이 id > 3을 하라는 것이다.
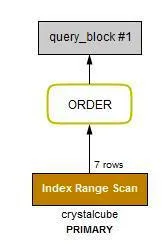
•
1 페이지부터 순차적으로 다음 페이지로 넘어갈때는 효율적이다.
•
다만 만약 id 값이 2 인 레코드가 삭제되어, 1 페이지의 id 가 1, 3, 4 인 경우 문제가 발생할 수 있다.
•
이때는 아래처럼 쿼리가 되야 한다.
많은 곳에서 아래 방식을 사용하라고 권장한다.
SELECT * FROM crystalcube WHERE id > 4 ORDER BY id LIMIT 3;
SQL
복사
•
즉, 순차적인 탐색이 아닌 Page Random Access 인 경우, 방법이 없다.
•
이 부분에 대해서는 추가적으로 방법을 연구해 봐야할 것 같다.
Limit
[Table #6] - Index(id), Index(age)
CREATE TABLE crystalcube
(
id INT(11) UNSIGNED PRIMARY KEY NOT NULL AUTO_INCREMENT,
age INT(11) NOT NULL DEFAULT 0,
name VARCHAR(32) NOT NULL,
comment VARCHAR(64),
extra VARCHAR(16),
INDEX(id),
INDEX(age)
);
SQL
복사
LIMIT 1;
EXPLAIN SELECT * from crystalcube LIMIT 1;
SQL
복사
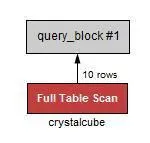
10 rows를 탐색
•
Full Table Scan이 발생한다.
•
LIMIT 1 을 하기 위해서는 어떤 기준이 필요한데 이 값이 없어서 발생되는 문제로 생각된다.
•
그렇다면 index인 id 를 가지고 정렬해서 LIMIT 1을 하면 Full Index Scan을 진행하며 1개의 row만을 탐색한다.
EXPLAIN SELECT * from crystalcube ORDER BY id LIMIT 1 ;
SQL
복사
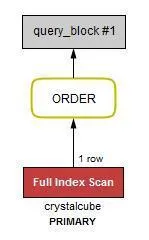
1 row를 탐색
Multi-Column Index 설정
CREATE TABLE `user` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(45) NOT NULL,
`age` INT NOT NULL,
`birthday` DATE NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_user_birthday_name_age` (`birthday`,`name`,`age`)
);
SQL
복사
•
user 테이블을 만들고 name, age, birthday column을 Multi-Column Index로 설정해줬다.
Multi-Column Index가 Index를 타는 방식
모든 Multi-Column Index를 WHERE에 사용했을 때
EXPLAIN ANALYZE SELECT * FROM user WHERE birthday = '1997-08-27' AND name = 'James' AND age = 1;
SQL
복사
•
EXPLAIN은 query의 수행 계획을 조회하기 위한 명령어다.
•
EXPLAIN ANALYZE는 EXPLAIN에 추가적으로 다음과 같은 정보를 우리에게 제공한다.
◦
query 수행 예상 비용
◦
결과 row의 예상 개수
◦
결과의 첫 번째 row가 반환되는 시간(milliseconds)
◦
모든 결과가 반환되는 시간(milliseconds)
◦
iterator가 반환하는 row의 개수
◦
loop가 수행되는 횟수
실행 결과

-> Covering index lookup on user using idx_user_birthday_name_age
(birthday=DATE'1997-08-27', name='James', age=1)
(cost=0.35 rows=1) (actual time=0.018..0.018 rows=0 loops=1)
SQL
복사
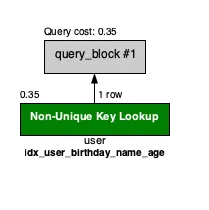
•
첫 번째 줄에서 해당 query가 index를 사용했으며, 어떤 index를 사용했는지 알려준다.
•
위의 query에서는 idx_user_birthday_name_age index를 사용했다.
범위 탐색을 했을 때
EXPLAIN ANALYZE SELECT * FROM user WHERE birthday >= '1997-08-27' AND name = 'James' AND age = 1;
SQL
복사
실행 결과

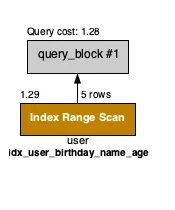
-> Filter: ((`user`.age = 1) and (`user`.`name` = 'James') and (`user`.birthday >= DATE'1997-08-27')) (cost=1.28 rows=1) (actual time=0.057..0.077 rows=1 loops=1)
-> Covering index range scan on user using idx_user_birthday_name_age over ('1997-08-27' <= birthday AND 'James' <= name AND 1 <= age) (cost=1.28 rows=5) (actual time=0.049..0.068 rows=5 loops=1)
SQL
복사
•
위 query 역시 index를 활용하였지만 이전의 예제와는 결과가 조금 다르다.
•
Index Lookup이 아닌 Index Range Scan을 수행했다.
•
하지만 위 결과에서는 무엇을 기준으로 range scan을 하고 있는지 나와있지 않다.
•
이를 확인하기 위해 아래와 같은 query를 다시 실행한다.
EXPLAIN FORMAT=json SELECT * FROM user WHERE birthday >= '1997-08-27' AND name = 'James' AND age = 1;
SQL
복사
실행 결과
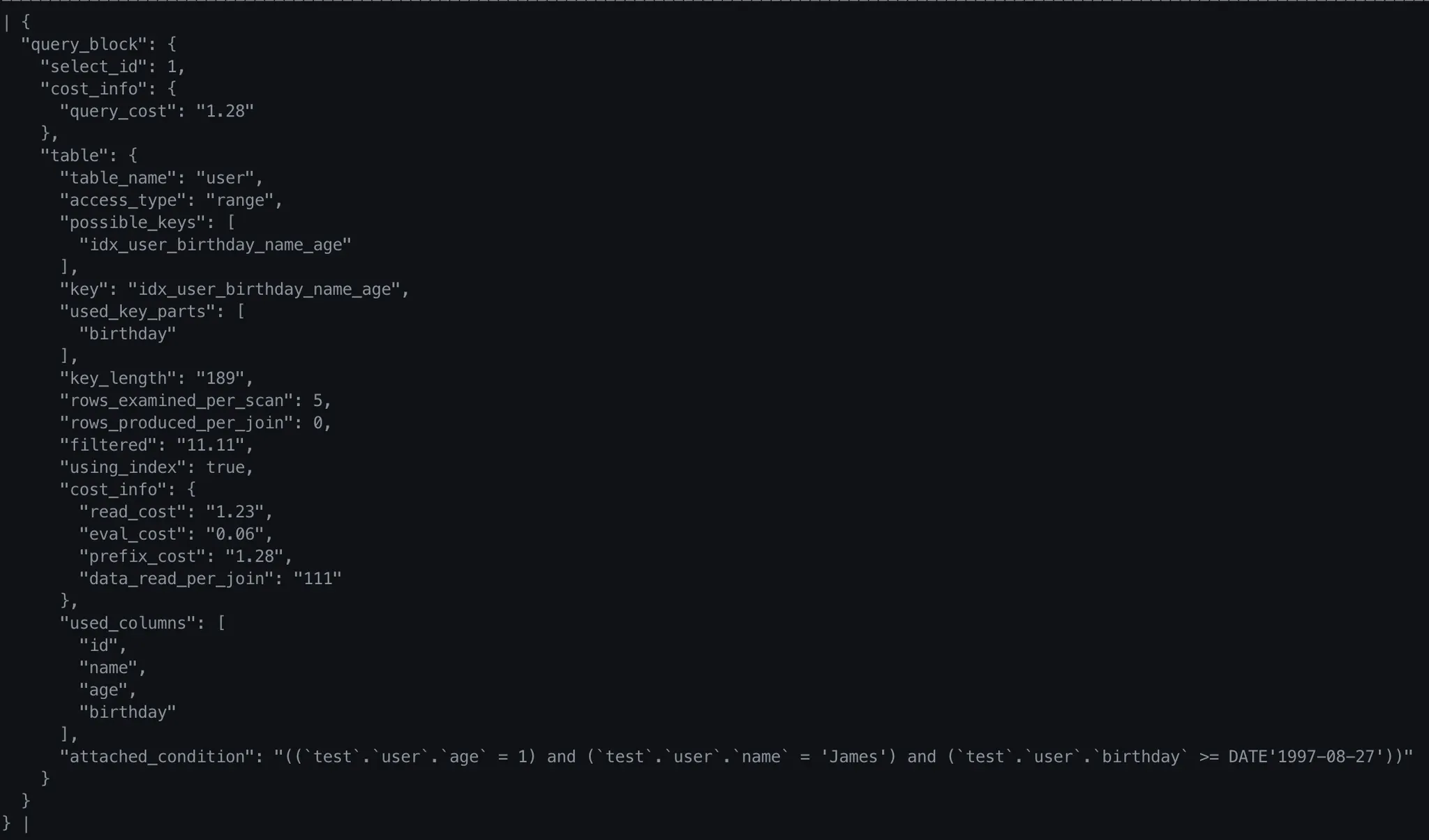
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "1.28"
},
"table": {
"table_name": "user",
"access_type": "range",
"possible_keys": [
"idx_user_birthday_name_age"
],
"key": "idx_user_birthday_name_age",
"used_key_parts": [
"birthday"
],
"key_length": "189",
"rows_examined_per_scan": 5,
"rows_produced_per_join": 0,
"filtered": "11.11",
"using_index": true,
"cost_info": {
"read_cost": "1.23",
"eval_cost": "0.06",
"prefix_cost": "1.28",
"data_read_per_join": "111"
},
"used_columns": [
"id",
"name",
"age",
"birthday"
],
"attached_condition": "((`test`.`user`.`age` = 1) and (`test`.`user`.`name` = 'James') and (`test`.`user`.`birthday` >= DATE'1997-08-27'))"
}
}
}
JSON
복사
•
기존 EXPLAIN ANALYZE를 사용했을 때보다 많은 정보들을 확인 할 수 있다.
•
그 중, key와 used_key_parts의 값을 확인해보면 idx_user_birthday_name_age index를 사용했고, 그 중 birthday column을 활용했다는 것을 확인할 수 있다.

문제점
•
수행한 query의 조건에는 해당 index를 구성하는 모든 column을 사용하였는데, 사용된 column은 birthday 하나다.
•
range scan의 경우, multi-column index여도 range scan에 사용된 column 이후의 index column은 사용되지 않는다.
Index Column 순서를 바꾸면 어떻게 될까?
ALTER TABLE `user`
DROP INDEX `idx_user_birthday_name_age` ,
ADD INDEX `idx_user_age_birthday_name` (`age`, `birthday`, `name`);
SQL
복사
EXPLAIN FORMAT=json SELECT * FROM user WHERE birthday >= '1997-08-27' AND name = 'James' AND age = 1;
SQL
복사
실행 결과
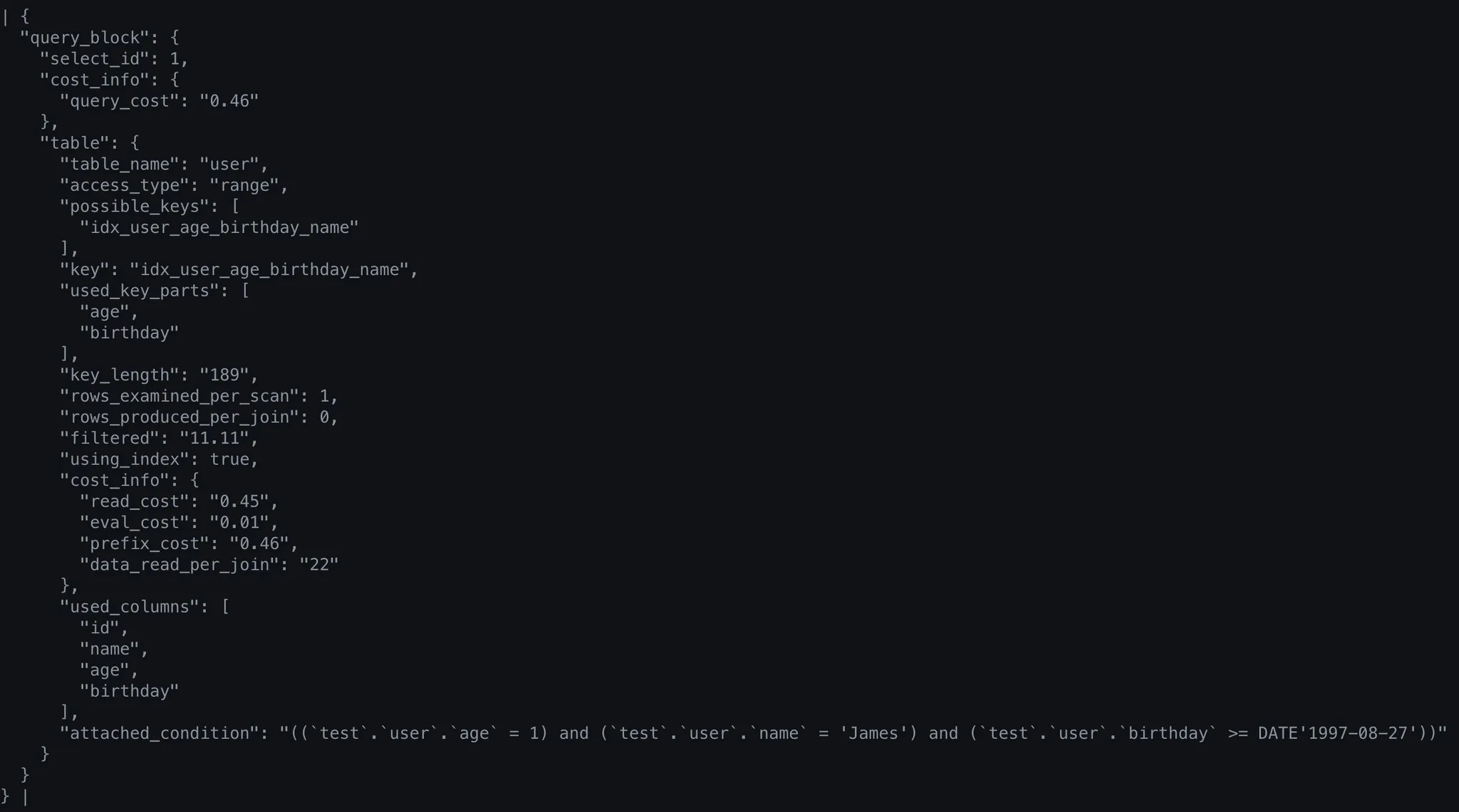
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "0.46"
},
"table": {
"table_name": "user",
"access_type": "range",
"possible_keys": [
"idx_user_age_birthday_name"
],
"key": "idx_user_age_birthday_name",
"used_key_parts": [
"age",
"birthday"
],
"key_length": "189",
"rows_examined_per_scan": 1,
"rows_produced_per_join": 0,
"filtered": "11.11",
"using_index": true,
"cost_info": {
"read_cost": "0.45",
"eval_cost": "0.01",
"prefix_cost": "0.46",
"data_read_per_join": "22"
},
"used_columns": [
"id",
"name",
"age",
"birthday"
],
"attached_condition": "((`test`.`user`.`age` = 1) and (`test`.`user`.`name` = 'James') and (`test`.`user`.`birthday` >= DATE'1997-08-27'))"
}
}
}
JSON
복사
•
used_key_parts를 보면, 이전과는 다르게 age와 birthday column를 사용한 것을 알 수 있다.
•
이 경우에는 먼저 age column을 Index Lookup한 후에 birthday column을 Index Range Scan했다는 것을 유추할 수 있다.
Range Scan에 사용되는 Column Index를 분리하면 어떨까?
ALTER TABLE `user`
DROP INDEX `idx_user_age_birthday_name` ,
ADD INDEX `idx_user_age_name` (`age`, `name`),
ADD INDEX `idx_birthday` (`birthday`);
SQL
복사
EXPLAIN FORMAT=json SELECT * FROM user WHERE birthday >= '1997-08-27' AND name = 'James' AND age = 1;
SQL
복사
실행 결과
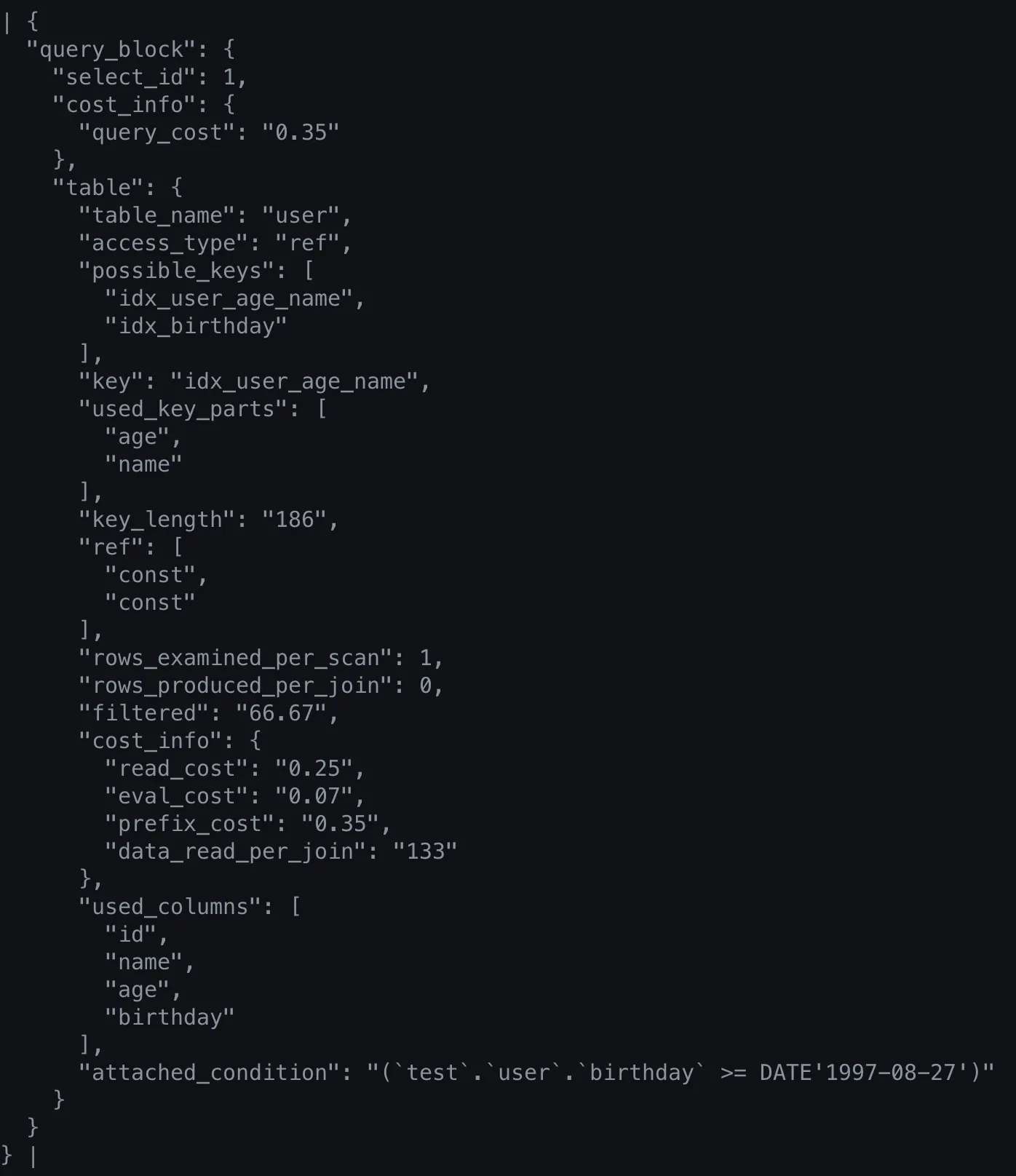
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "0.35"
},
"table": {
"table_name": "user",
"access_type": "ref",
"possible_keys": [
"idx_user_age_name",
"idx_birthday"
],
"key": "idx_user_age_name",
"used_key_parts": [
"age",
"name"
],
"key_length": "186",
"ref": [
"const",
"const"
],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 0,
"filtered": "66.67",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "0.07",
"prefix_cost": "0.35",
"data_read_per_join": "133"
},
"used_columns": [
"id",
"name",
"age",
"birthday"
],
"attached_condition": "(`test`.`user`.`birthday` >= DATE'1997-08-27')"
}
}
}
JSON
복사
•
used_key_parts에서 사용된 column은 age와 name인 것을 알 수 있다.
•
index를 두 개로 분리하였는데도 birthday column이 사용되지 않은 이유는 무엇일까?
•
•
실제로 그렇게 동작하는지 다음의 query를 수행해 보겠다.
가장 적은 수의 row를 찾는 index 사용
•
참고로 해당 테이블에서 birthday column의 최대 값은 '2023-08-27'이다.
•
즉, range scan으로 찾을 수 있는 row는 0개지만 나머지 조건에 해당하는 row는 적어도 하나 이상이 존재한다.
EXPLAIN FORMAT=json SELECT * FROM user WHERE birthday >= '2024-08-27' AND name = 'James' AND age = 1;
SQL
복사
실행 결과
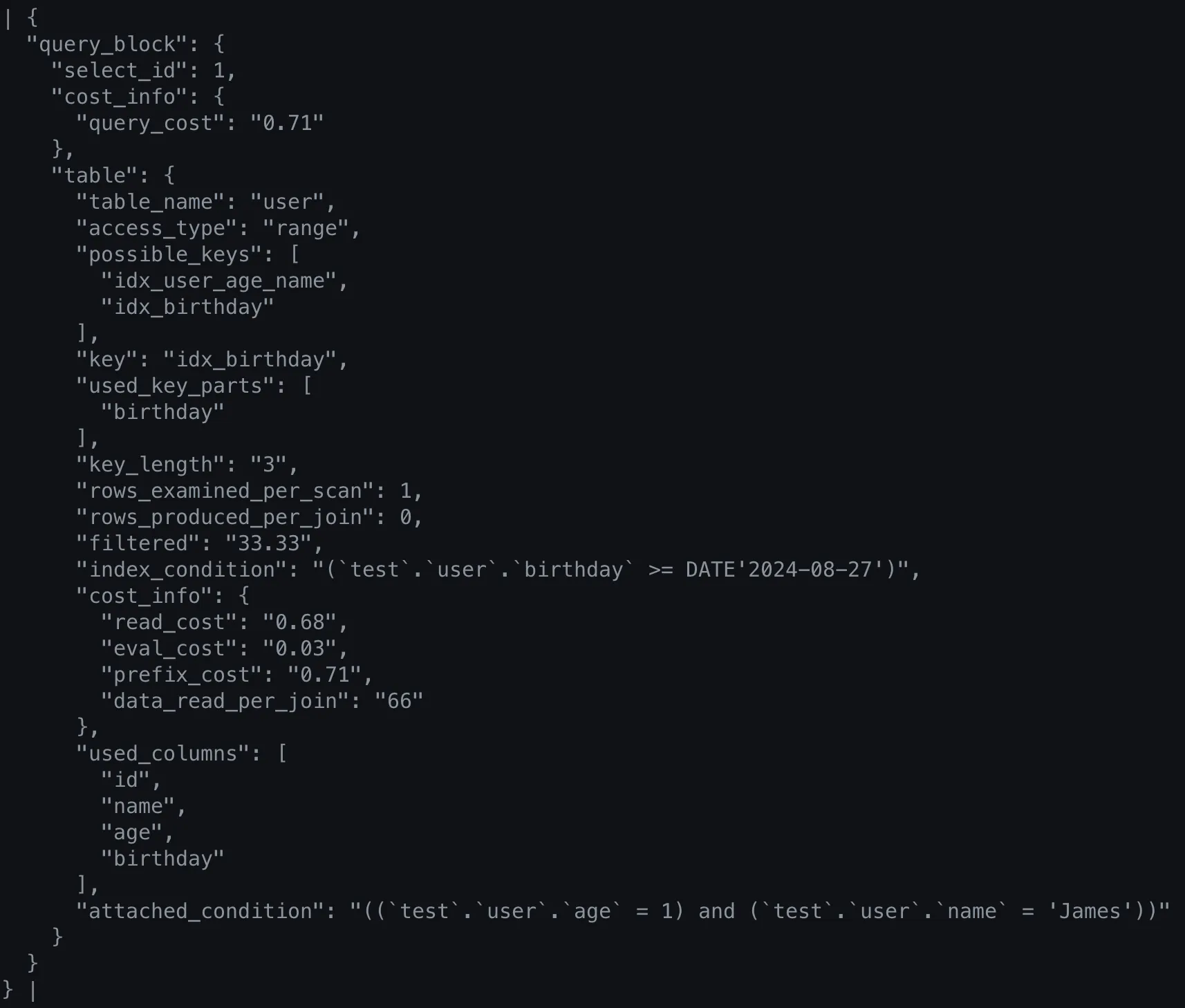
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "0.71"
},
"table": {
"table_name": "user",
"access_type": "range",
"possible_keys": [
"idx_user_age_name",
"idx_birthday"
],
"key": "idx_birthday",
"used_key_parts": [
"birthday"
],
"key_length": "3",
"rows_examined_per_scan": 1,
"rows_produced_per_join": 0,
"filtered": "33.33",
"index_condition": "(`test`.`user`.`birthday` >= DATE'2024-08-27')",
"cost_info": {
"read_cost": "0.68",
"eval_cost": "0.03",
"prefix_cost": "0.71",
"data_read_per_join": "66"
},
"used_columns": [
"id",
"name",
"age",
"birthday"
],
"attached_condition": "((`test`.`user`.`age` = 1) and (`test`.`user`.`name` = 'James'))"
}
}
}
JSON
복사
•
이번에는 used_key_parts에 age, name이 아닌, birthday가 들어간 것을 볼 수 있다.
•
문서에서 말한 것과 같이, 더 적은 row를 찾을 수 있는 index를 선택하고 나머지 조건은 index를 사용하지 않고 filtering하여 결과를 반환한다.
요약
•
Multi-Column Index의 첫 번째 column이 range scan에만 사용될 경우, 나머지 column들은 전혀 활용되지 못한다.
•







