
Index를 이용한 통계 데이터 GET API 개선
•
•
이를 해결하기 위해 API 성능을 다 조사해본 결과 통계 데이터를 가져오는 API가 상당히 오래 걸리는 것을 확인했다.
기존 방식
const statistics = await this.statisticsRepository.find({
where: { gender, weight: betweenWeight },
order: { SBD_volume: "ASC" },
});
...
TypeScript
복사
SELECT * FROM `SBD_statistics` `SBD_statistics` WHERE (`SBD_statistics`.`gender` = 0 AND `SBD_statistics`.`weight` BETWEEN 93.01 AND 105)
TypeScript
복사
•
사용자의 성별이 남성, 체중이 100kg 일 경우, 성별이 남자면서 체중이 93~105kg 인 모든 사용자의 3대 운동 총량을 가져옵니다. 그 후에, 3대 운동 총량을 기준으로 정렬합니다.
•
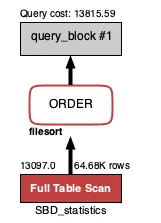
하지만 이럴 경우 체중이 93~105kg인 사용자들이 테이블에 여기저기 흩어져 있기 때문에 Full Table Scan을 통해 모든 사용자 정보를 가져옵니다.
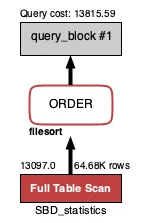
Query cost: 13815.59
개선 방법
아이디어
•
처음에는 체중을 정렬 시킨 상태로 between으로 가져오는 것이 휠씬 빠를 것이라 생각했다.
◦
between 93~105를 Index Range Scan으로 쭉 가져오는게 빠르고, 후에 정렬을 안해줘도 되기 때문이고 생각했다.
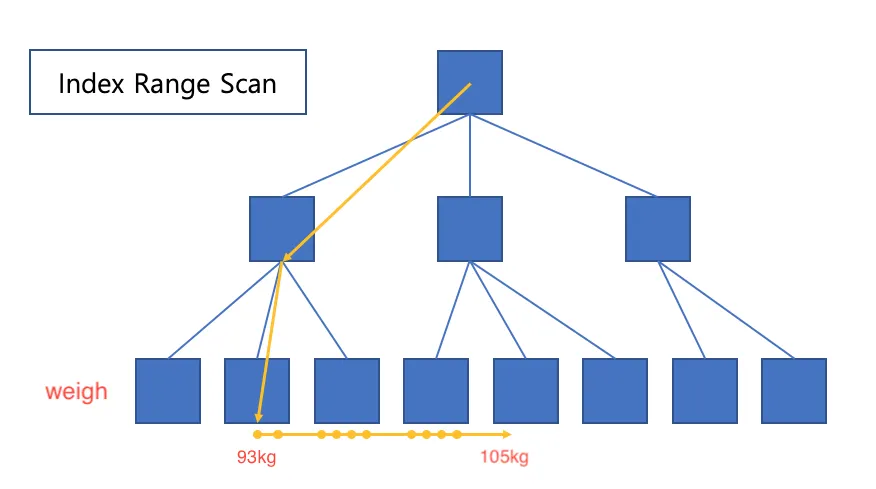
Single Column Index (weight)
•
하지만 실험 결과 성별로 인해 Index Range Scan을 과도하게 길게 한다는 것을 파악했다.

Query cost: 10190.21
◦
Full Table Scan보단 나아졌지만 여전히 느린 모습.
Single Column Index (gender, weight)
•
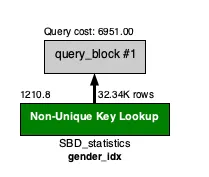
오히려 성별을 인덱싱 시킨 상태로 가져오는 것이 휠씬 빠른 모습을 확인했다.
•
non-unique index로 가져오기 때문인거같다. 하지만 성별의 경우 0, 1 두개로만 나뉘는데 아무리 non-unique index라지만 이게 정말 빠를까라는 생각을 했다.
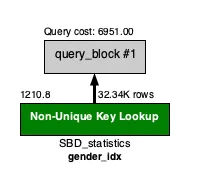
Query cost: 6951.00
Multi Column Index (gender, weight)
•
그래서 성별과 체중의 Multi Column Index을 이용해봤다.
ALTER TABLE SBD_statistics ADD INDEX gender_weight_idx (gender, weight);
SQL
복사

const statistics = await this.statisticsRepository.find({
where: { gender, weight: betweenWeight },
// order: { SBD_volume: "ASC" }, index로 인해 정렬이 필요 없어진다.
});
...
TypeScript
복사
.png&blockId=00d037ad-5a17-47ab-b32f-e927af8d8be5)

Query cost: 3253.21
•
하지만 실험 결과, 가져오는 데이터의 rows가 많아질수록 속도가 급격히 느려지는 것을 확인할 수 있었다.
•
심지어 가져오는 데이터의 rows가 일정 수치를 넘어갈 경우 Full Table Scan으로 가져오는 것을 확인할 수 있다.
gender | weight | query cost | rows | duration | Scan Type |
0 | 59~66kg | 3253 | 2.32k | 0.0047 | Index Range |
0 | 66~74kg | 6919 | 4.94k | 0.0088 | Index Range |
0 | 74~83kg | 9728 | 6.94k | 0.0117 | Index Range |
0 | 83~93kg | 10459 | 7.47k | 0.0135 | Index Range |
0 | 93~105kg | 8704 | 6.22k | 0.0120 | Index Range |
0 | 105~120kg | 5525 | 3.95k | 0.0069 | Index Range |
0 | 83~105kg | 13097 | 64.68k | 0.0356 | Full Table |
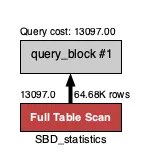
Query cost: 13097
Multi-Block Read
왜 Full Table Scan으로 가져올까?
•
알아본 결과 Multi-Block Read 관련 이슈였다.
◦
특정 call이 일어나면 디스크에서 Block들을 읽어보고, 버퍼 캐시에 저장한다. 하지만 읽어올 때 Block을 하나씩 읽어오는 건 아니고 경우에 따라 다르다.
◦
Single-Block은 한번의 call에서 하나의 데이터 Block만 읽어와 메모리에 적재하는 방법이다. 인덱스를 통한 table access일 때 일어난다.
◦
Multi-Block은 한번의 call에서 인접한 블록들을 다 같이 읽어버린다. extent 범위(OS가 지원하는 최대 범위는 1MB)내면 다 읽어 들인다.
•
DB의 Block은 일반적으로 8KB이고 Multi-Block Read는 한번에 1MB(128개의 8KB Block)을 읽어오는 반면에 Single-Block Read은 8KB → 8KB → 8KB 이런식으로 하나씩 조회하기 때문에 느리다.
◦
Index Scan으로 작은 용량의 데이터를 가져올 땐 Index를 이용해 실제 row가 포함된 하나의 데이터베이스 Block만 조회하기 때문에 상관없지만, 대용량 데이터를 가져올 땐 여러 Block을 조회하기 때문에 느리다.


요약
•
Full Table Scan은 Multi-Block Read가 가능하지만 Index Full Scan은 Leaf Block을 일일이 방문하기 때문에 Single-Block Read 밖에 할 수 없다. 그래서 때로는 Full Table Scan의 성능이 더 좋을 때가 있다고 한다.
실험 결과
Query cost
•
No Index → Single Column Index (gender)
•
13815.59 → 6951.00
◦
약 49.6%%의 성능 향상
Query cost: 13815.59
Query cost: 6951.00
k6 (VUs : 150)
No Index
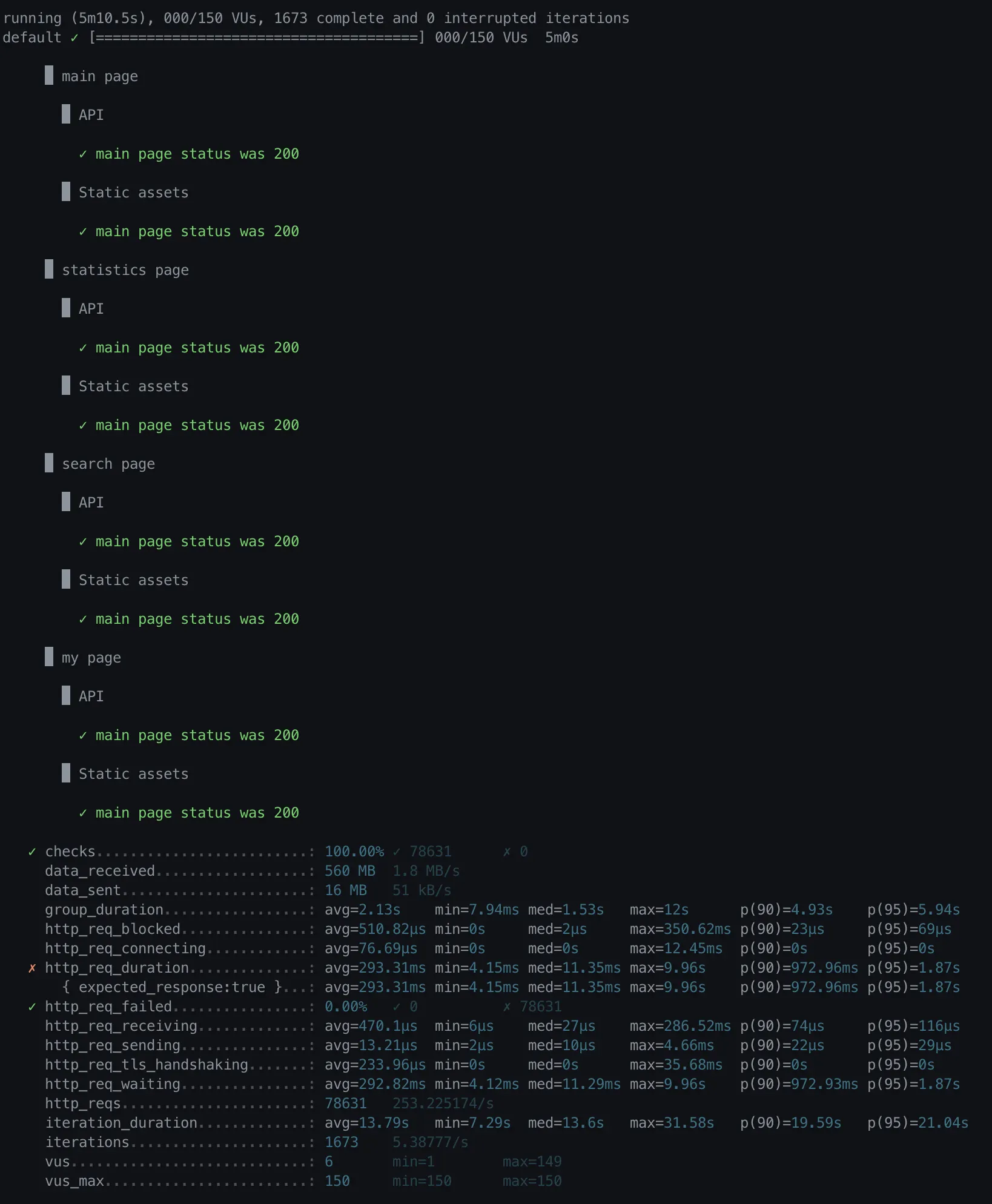
•
http_req_duration
◦
avg = 293.31ms
◦
p(90) = 972.96ms
◦
p(95) = 1.87s

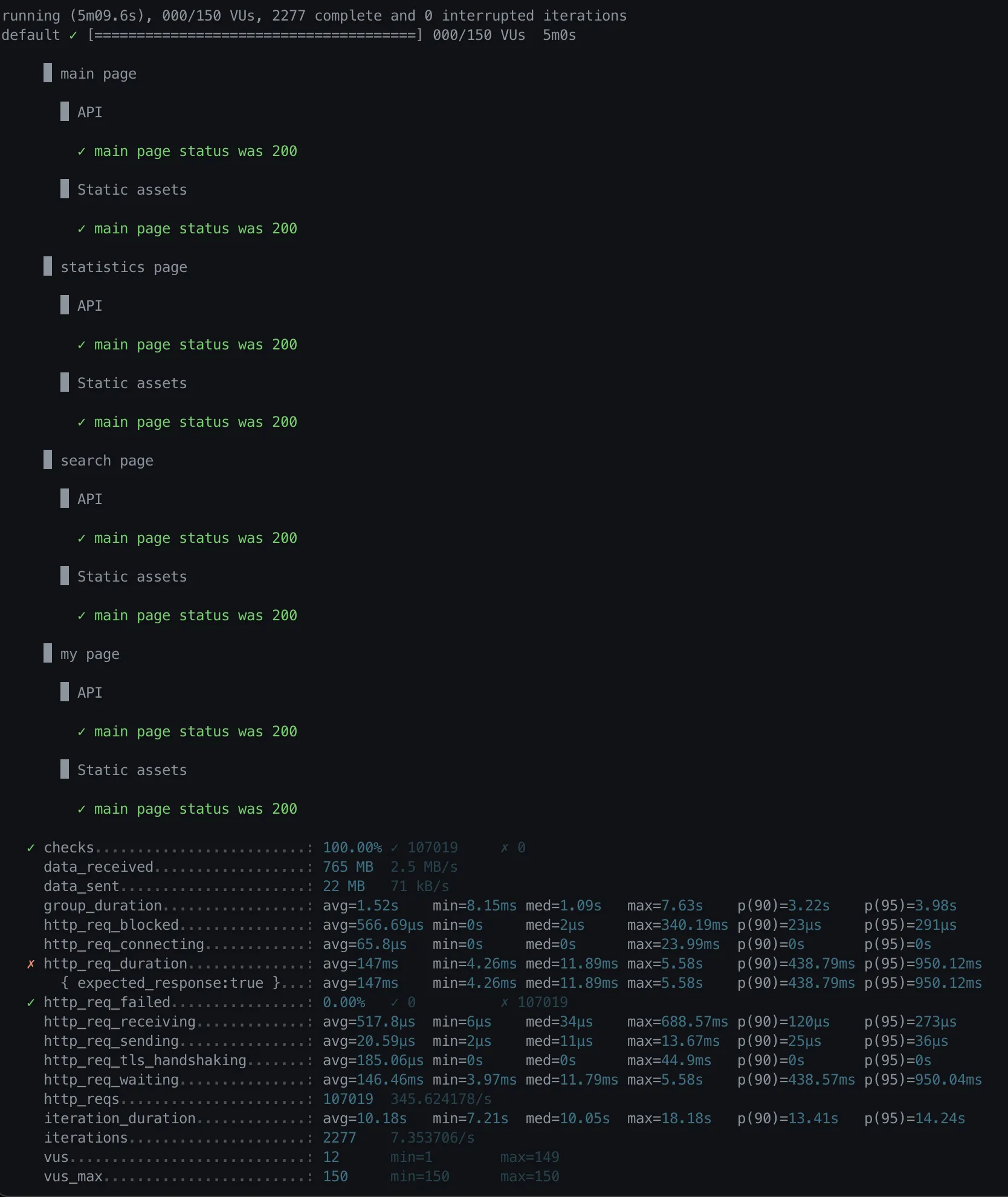
Multi Column Index (gender, weigh)
•
http_req_duration
◦
avg = 147ms
◦
p(90) = 438.79ms
◦
p(95) = 950.12ms

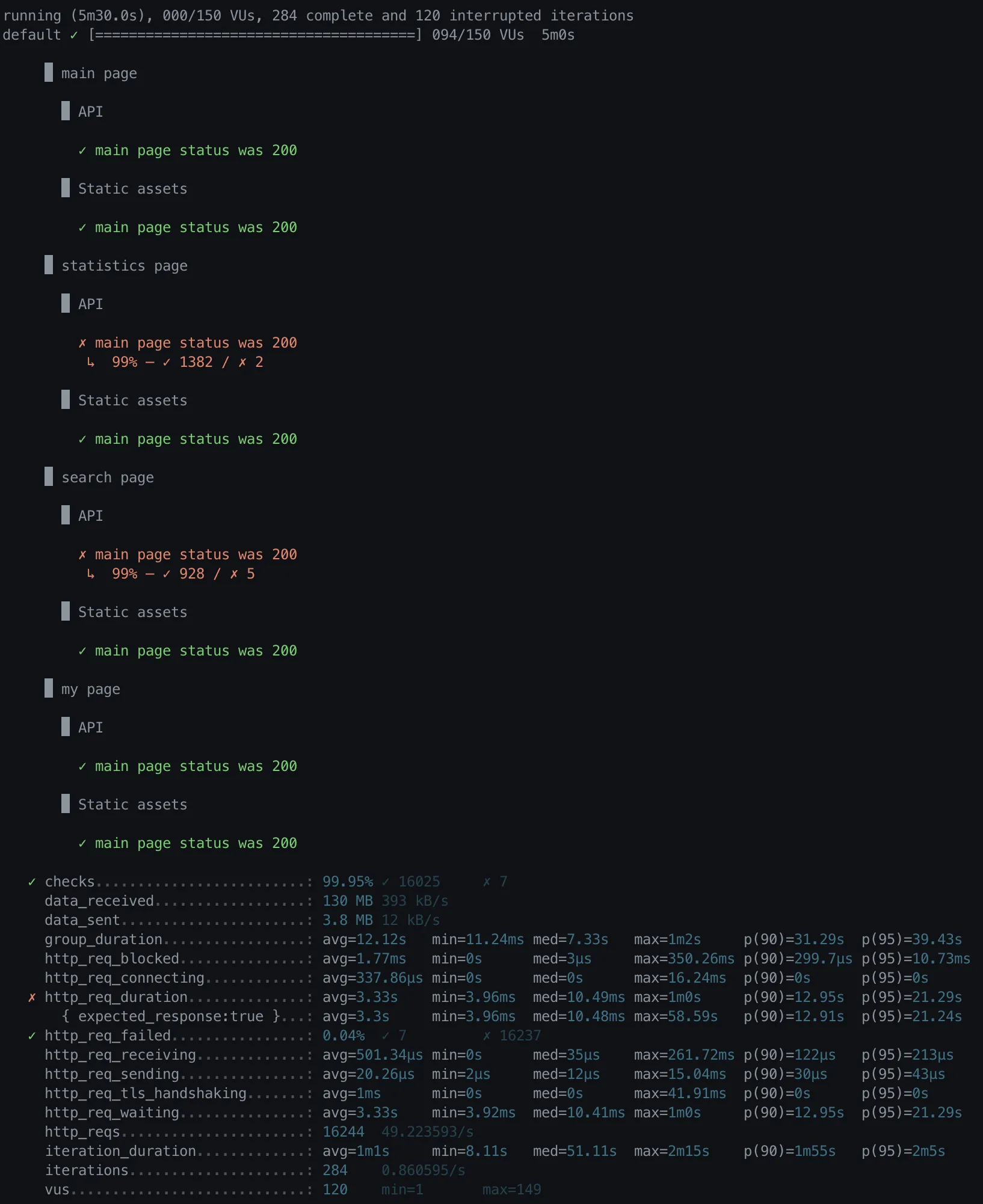
Single Column Index (gender)
•
http_req_duration
◦
avg = 3.33s
◦
p(90) = 12.95s
◦
p(95) = 21.29s

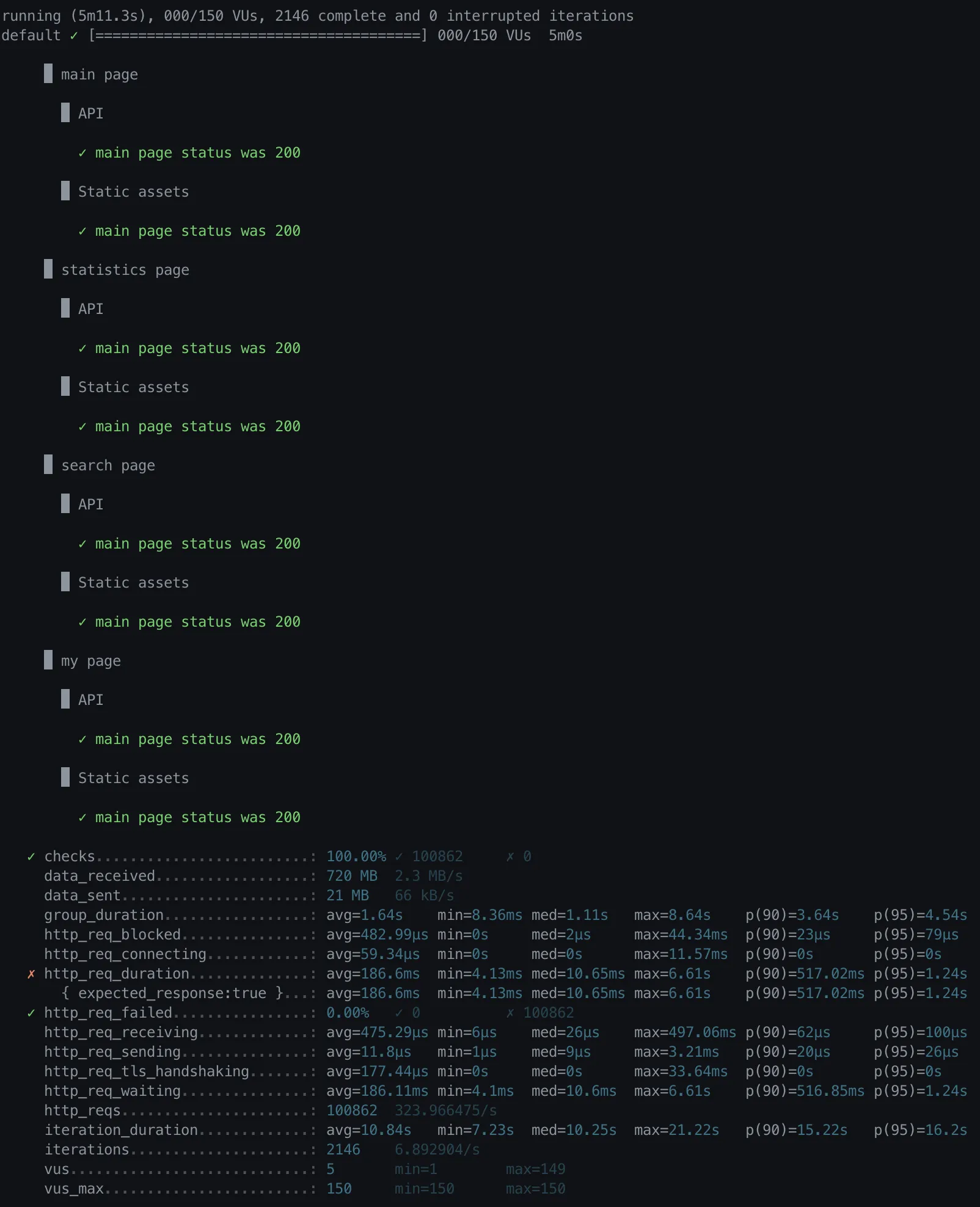
Single Column Index (gender, weight)
•
http_req_duration
◦
avg = 186.6ms
◦
p(90) = 517.02ms
◦
p(95) =1.24s

http_req_duration 요약 (No Index → Multi Column Index)
avg
•
293.31ms → 147ms
◦
약 49.8%의 성능 향상
p(90)
•
972.96ms → 438.79ms
◦
약 54.9%의 성능 향상
p(95)
•
1.87s → 950.12ms
◦
약 49.1%의 성능 향상
http_req_duration 요약 (Single Column Index → Multi Column Index)
avg
•
186.6ms → 147ms
◦
약 21.2%의 성능 향상
p(90)
•
517.02ms → 438.79ms
◦
약 15.1%의 성능 향상
p(95)
•
1.24s → 950.12ms
◦
약 23.3%의 성능 향상
결론
•
Multi Column Index를 이용해 Index Range Scan을 하는 경우가 특정 조건에선 빠르지만, 추후 통계 데이터가 계속 쌓이며 데이터의 수가 많아질수록 Multi Column Index가 불리하다고 생각된다.
•
그러므로 데이터 수와 상관 없이 항상 일정한 속도를 보장하는 Single Column Index(gender, weight)가 타당하지만 데이터 수가 적은 현재로서는 Multi Column Index(gender, weight)가 Single Column Index보다 약 15~23%가량 빠르므로 Multi Column Index를 채택했다.
•
추후 서비스가 확장되어 데이터가 많아질 경우 Single Column Index를 고려해볼 수 있을 꺼 같다.